


Have you ever typed a quick description into a prompt box, hit enter, and sat back as a fully formed track pours out of your speakers? It honestly feels a bit like magic. You ask for a walking bassline, jazzy drums, and a breathy vocal, and a few moments later, it actually exists.
But it is not magic at all. It is pattern learning operating on a massive scale.
AI music models are trained to understand the deep relationships between sounds, structures, instruments, styles, and human language. When you use these tools, the model is not “composing” the way a human musician does. It is generating new audio based on statistical patterns it learned from millions of training examples.
If you want to actually use AI music generation in real projects, you need to understand how it works under the hood. This guide breaks down the core concepts, the different models available, and what creators need to know to get the best results without losing their own creative voice.
What Exactly Is AI Music Generation?
At its core, AI music generation is the use of artificial intelligence to create musical material. That material could be a simple two-second drum loop, a background score for a documentary, or a fully mixed pop song draft complete with lyrics.
Depending on the specific system you are using, you might feed the AI a variety of inputs. You could use a text prompt, an existing melody you hummed into your phone, a chord progression, a reference track, or even just an image or a video clip. In return, the output might be raw audio, editable MIDI data, isolated instrument stems, or a final stereo mix.
The system works by studying how musical elements relate to each other. It learns that certain drum patterns belong in specific genres. It learns that a prompt asking for a “cinematic” feel usually requires sweeping strings and heavy percussion.
However, the model is not feeling the mood. It does not understand human emotion. It is simply mapping your instructions to the musical patterns it has memorized. AI can produce incredibly convincing results, but it completely lacks an understanding of intention, taste, or audience.
Why This Technology Matters Right Now
AI music generation matters because it drastically lowers the barrier to creating usable musical ideas.
Think about the workflow of modern creators. A filmmaker can test the emotional weight of a scene with custom background music before they ever hire a composer. A podcaster can draft a unique intro theme. A songwriter experiencing writer’s block can use a model to brainstorm fresh chord progressions or unexpected textures.
This does not make human musicians obsolete. Instead, it changes where the real value sits. When generative music AI makes the act of producing basic sounds effortless, human creative judgment becomes the most important skill. The talent lies in knowing what track actually belongs in the scene, what emotional beat supports the message, and what sounds too generic and needs to be thrown away.
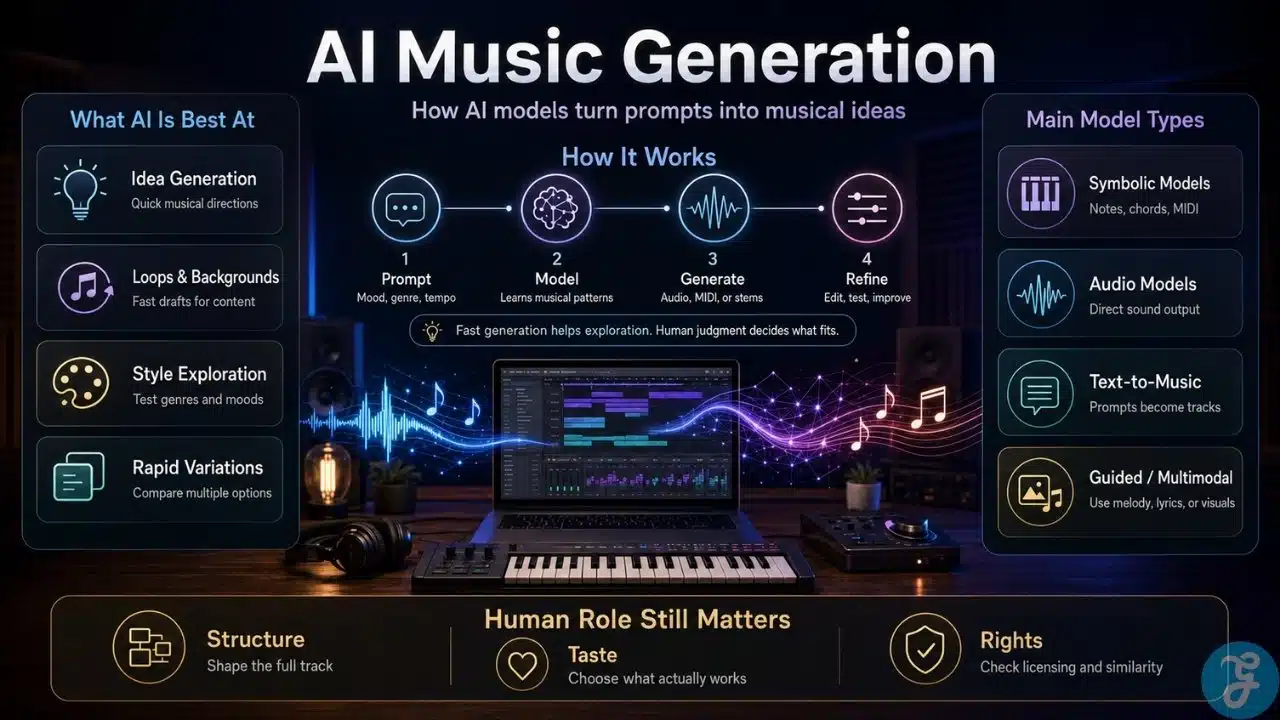
How the Generation Process Actually Works
While the technology is incredibly complex, most generative systems follow a very similar overarching process.
First, the model goes through a massive training phase. It absorbs colossal amounts of audio data, learning the intricate patterns of rhythm, pitch, timbre, harmony, and song structure. Second, the model receives your input, whether that is a text prompt or an audio reference.
Third, it translates that input into an internal mathematical representation. The AI does not “hear” your prompt. It converts your words into data points that guide the generation engine. Fourth, the model builds the musical material. Finally, that data is decoded and rendered into an audio file or MIDI sequence that you can actually listen to and edit.
The Main Types of AI Music Models
Not all music AI tools are built the same way. The biggest differentiator is the type of musical information they are designed to spit out.
Symbolic Music Models
These systems generate musical instructions rather than finished audio waves. They produce things like notes, chords, rhythm patterns, or MIDI data. These are incredibly useful for producers because the output is entirely editable. You can take a generated MIDI melody, drop it into your digital audio workstation, and assign it to any synthesizer you own. The downside is that you have to do the sound design and mixing yourself.
Audio Generation Models
This is what most people picture when they think of AI music. You give the model a prompt, and it generates direct, listenable sound. These models are incredibly fast and accessible, making them perfect for users who do not know how to mix or produce. The trade-off is a severe lack of control. Once the audio is baked into a final file, it is extremely difficult to isolate and change a single bad note or a loud cymbal crash.
Text-to-Music Models
These models act as a translator between human language and musical audio. You might describe the genre, mood, tempo, and instruments you want. The model then has to connect abstract words like “reflective” or “dark” to specific choices in harmony and pacing. This is powerful, but prompts can be notoriously vague, leading to unpredictable results.
Melody-Guided Models
Some systems allow you to use an existing piece of audio as an anchor. You can hum a rough tune into your microphone and ask the AI to turn it into a full jazz arrangement. This keeps your original human idea at the center of the creative process, using the AI simply as an arranger or backing band.
Stem and Arrangement Models
Professional production rarely ends with a single stereo file. Stem models generate isolated parts of a track, giving you separate files for the drums, the bass, the vocals, and the keys. By 2026, advanced stem separation and generation have become vital features in platforms like Suno, allowing producers to mute, replace, or heavily edit individual elements without ruining the rest of the song.
What the AI Actually Learns (And What It Misses)
These systems learn statistical relationships, not musical rules.
An AI might learn that electronic dance music typically features strong kick drums and massive bass drops. It might learn that pop songs rely on repeating chorus structures. Because it learns through statistics, the output can often sound sonically convincing while making bizarre structural choices.
You might get a track with a fantastic groove that completely fails to develop over three minutes. You might get a song that matches the requested genre perfectly but entirely misses the emotional point of your prompt. Pattern fluency is simply not the same thing as musical judgment.
Where AI Excels and Where It Struggles
Generative AI is at its absolute best when used for exploration, drafting, and rapid iteration. It is an amazing tool for brainstorming musical directions, creating ambient background beds, generating sound design elements, and supporting non-musicians during the early stages of a project. It reduces the cost and time associated with trying out wild ideas.
However, it still struggles with long-form structure. A 15-second clip might sound like a Billboard hit, but turning that into a cohesive three-minute track with tension, release, and a satisfying bridge is a major hurdle. Vocals remain another massive challenge. While the voices sound increasingly realistic, controlling the phrasing, the emotional delivery, and the exact pronunciation of lyrics is still highly unpredictable.
How to Write Better Music Prompts
If you want better results from music AI tools, you have to write highly specific prompts. Asking a model to “make happy music” is a recipe for generic elevator music.
A strong prompt needs a clear framework. You should define the purpose of the music, the core mood, the specific genre, the approximate tempo, and the exact instruments you want to hear.
For example, a much better prompt would be: “Bright indie pop instrumental for a tech product launch, medium tempo, featuring clean electric guitars, light acoustic drums, and a warm analog synth pad. Upbeat and optimistic, strictly no vocals.” This gives the engine a defined roadmap. It is also best practice to describe the sonic qualities you want rather than asking the AI to copy the exact style of a living, copyrighted artist.
The Realities of Copyright and Ethics
Using AI for personal brainstorming is one thing, but using it for commercial client work introduces serious legal questions.
You must always check the licensing terms of the platform you are using. Some tools grant you full commercial rights if you are on a paid tier, while others strictly forbid using their output in monetized content. Furthermore, generating music that closely imitates the recognizable voice or signature style of a specific artist can lead to significant ethical and legal trouble, even if the platform technically allows you to type their name into the prompt box.
If the generated music is going to affect your brand’s trust or identity, you need to review the source data policies and usage rights very carefully.
The Future Belongs to the Editors
We have moved past the initial shock of AI being able to generate a song. The current and future landscape of generative music AI is entirely focused on granular control.
Creators do not just want a randomized song generator anymore. They want collaborative environments where they can generate a verse, manually tweak the MIDI data, ask the AI to harmonize a chorus, and then extract the vocal stems for external mixing.
AI music models will continue to become more sophisticated, but the human role is not going anywhere. It is simply shifting away from raw sound creation and moving toward direction, curation, editing, and final judgment. When anyone in the world can generate a song in ten seconds, the true advantage belongs to the person who knows exactly what a project actually needs.






















