For most software companies in 2026, the line item that keeps a CFO awake is no longer cloud compute. It is the LLM bill. This is a field analysis of where AI budgets actually leak and the five levers the operators who fix them keep pulling.
Industry estimates put enterprise LLM spending at roughly $8.4 billion in 2025, more than double the previous year’s figure, with consensus forecasts suggesting another doubling is plausible by the end of 2026. What makes this category dangerous is not its size—most engineering organizations expected the growth—but its opacity. Provider dashboards return a single aggregated number per day. There is no per-feature breakdown, no per-team allocation, no clean way to see which prompt is responsible for which dollar. Founders sign off on bills they cannot decompose.
Field reports from operators who have audited their stacks suggest that 40 to 60 percent of token budgets in production LLM applications are pure waste — money paid for capability never used or for inefficiencies nobody priced at design time. That figure is consistent across teams from venture-backed SaaS startups to enterprise platform groups, and it is the central number every founder reading this should take seriously.
This piece is a synthesis of what the operators who have closed that gap report, what the underlying research now shows, and what founders should be asking their CTOs this quarter.
The visibility problem
The first reason LLM bills run hot is that almost no team instruments them properly before scaling.
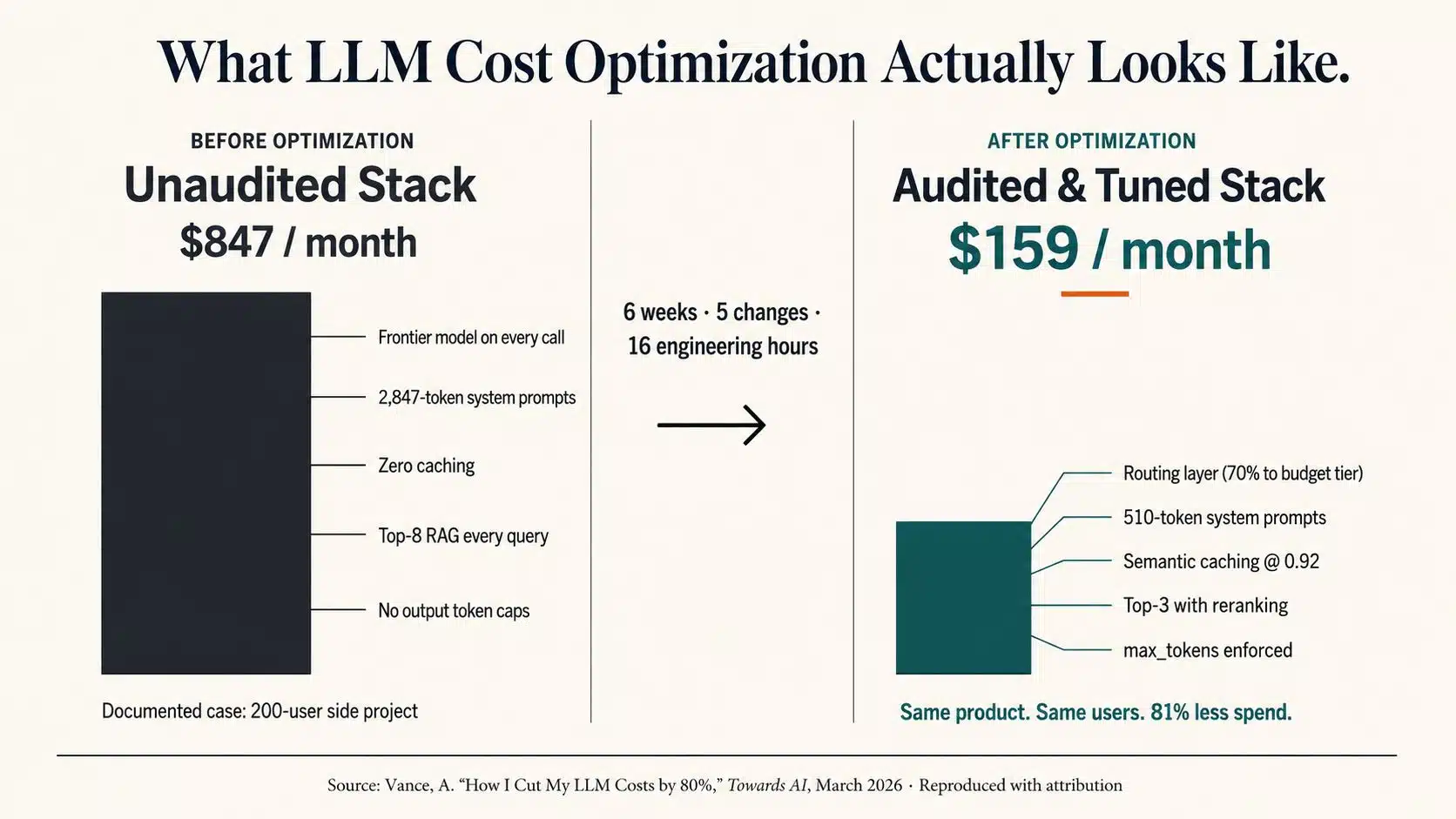
A widely circulated case study published earlier this year by engineer Ari Vance in Towards AI documents one such audit: a side project with roughly 200 active users producing an $847 monthly bill, almost none of which was attributable to any single feature. After six weeks of optimization, the same product served the same users for under $160—an 81 percent reduction the author traces to five distinct architectural changes, with no measurable degradation in user-facing quality. The full account, including code samples and trade-off analysis, is worth reading in the original.
What that case study makes vivid is a structural truth about LLM pricing: output tokens cost three to ten times more than input tokens, depending on model and provider, and provider pricing pages typically lead with the cheaper input number. A chatbot that generates twice as much text as its users send is paying close to nine times the advertised rate on actual unit economics.
The operators who have closed cost gaps started in the same place: they instrumented every LLM call before they touched anything else. Tools like Langfuse, Helicone, and Datadog’s LLM observability layer have made this a two-hour setup, not a quarter-long project. Without that data layer, every other optimization is guesswork.
The 120x variance
The second structural fact founders should internalize is the cost spread between models.
In Q1 2026, the per-token cost of the cheapest production-grade models DeepSeek V3, Claude Haiku, and GPT-4o-mini versus the most expensive GPT-5.2-class, Claude Opus, and Gemini Ultra differs by roughly 120 times on input pricing alone and substantially more once output tokens enter the math. The gap has widened, not narrowed, since DeepSeek’s R1 release in early 2025 forced aggressive pricing across the field.
The implication for founders is direct: the same task, performed correctly, can cost a few cents on one model and several dollars on another. That is not a tuning problem. It is an architecture problem.
The clearest research support is RouteLLM, presented at ICLR 2025, which showed a well-trained matrix factorization router achieving 95 percent of GPT-4 quality while routing only 14 to 26 percent of requests to the frontier model — a 75 to 85 percent reduction in cost on routed workloads, with no quality target missed. As of mid-2026, roughly 37 percent of enterprises with production AI workloads run five or more models in their stack, according to industry surveys. The remainder are still defaulting to one model for everything.
The five leaks
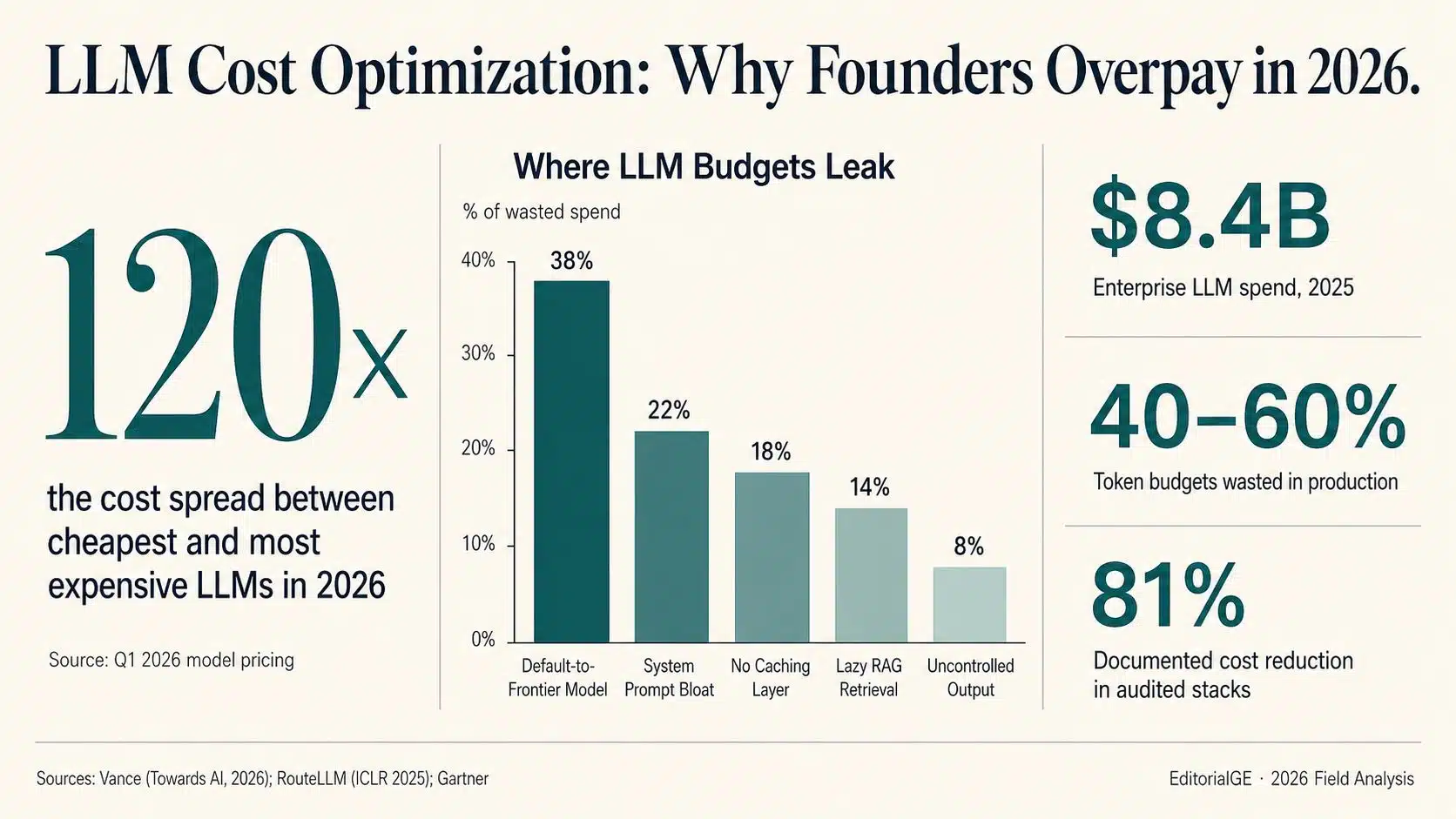
Across the operator accounts, research papers, and vendor benchmarks now in the public record, the same five cost leaks appear in roughly the same order of magnitude.
1. Default-to-frontier model selection. Consistently the single largest leak, accounting for roughly a third or more of wasted spend in audited stacks. Teams ship with one capable model typically GPT-4o or Claude Sonnet and route every call to it, including intent classification, simple summarization, and structured data extraction that lighter models handle with identical accuracy. Operators who add a routing layer typically report 30 to 70 percent cost reductions on the routed slice, with some endpoints clearing 90 percent.
2. System prompt bloat. Production system prompts grow over time. Edge-case handling, reworded instructions, redundant examples — each addition feels justified in isolation. Audits routinely find prompts that have ballooned from 500 tokens to 2,000-plus over six months. Because system prompts fire on every call, the compounding waste is severe. A 1,200-to-400-token cut on a prompt running 5,000 times a day clears roughly $60 a month from a single endpoint. For RAG-heavy applications, automated compression via Microsoft Research’s LLMLingua-2 reports up to 20x compression with under two percent quality loss on standard benchmarks.
3. No caching layer. Most production applications answer the same questions repeatedly under different phrasings. Provider-side prompt caching, Anthropic at 90 percent off cached reads and OpenAI at 50 percent, handles consistent system prompts automatically. Semantic caching, which embeds incoming queries and returns previously generated answers when similarity exceeds a threshold around 0.92, handles user-side repetition. A VentureBeat-documented enterprise deployment cut a $47,000 monthly bill to $12,700 — a 73 percent reduction — by replacing exact-match caching with semantic caching, lifting the hit rate from 18 percent to 67 percent.
4. Lazy RAG retrieval. A naive RAG pipeline retrieves a fixed top-K (commonly 8) for every query, regardless of complexity. The result is both expensive and worse: longer contexts trigger the well-documented “lost in the middle” effect that degrades model attention. Production RAG architectures retrieve broadly the top 20—then rerank with a cheap cross-encoder, then forward only three to five chunks to the LLM. The token reduction is typically 50 to 70 percent, and answer quality, measured against frameworks such as RAGAS, generally improves rather than slips. This is the rare cost lever where the optimization is also a product upgrade.
5. Uncontrolled output tokens. The cheapest fix on the list. Many production endpoints — particularly classifiers and structured-extraction calls — never set a max_tokens cap and never enforce structured output formats. The result is models writing paragraphs of justification when a single JSON object was needed. Constraining output and requiring structured responses routinely cuts non-conversational endpoint costs by 60 to 80 percent.
The honesty layer
The published operator accounts do not pretend these changes are free of trade-offs. The same case studies that report 80-percent cost reductions also document quality slippage in roughly six to eight percent of cases, typically routing failures on ambiguous queries, stale cached responses after a product update, and budget-model gaps on domain-specific terminology. The operators who report durable savings also report investing engineering time into evaluation sets (RAGAS for RAG, custom case suites for routed endpoints) and continuous monitoring such as correction-to-completion ratios and rolling hallucination-rate windows.
In other words, this is not a zero-cost game. It is engineering rigor applied to a new layer of the stack closer in spirit to database indexing than to a one-time refactor.
What founders should ask their CTOs this quarter
For founders reading this without deep technical staff, the practical question is not “How do we implement these levers?” but “Are we already leaking, and how would we know?”
Four questions worth raising in the next engineering review:
- Do we log token usage by feature, not just by day? If the answer is no, the company is flying blind on its second-largest variable cost.
- What percentage of our LLM calls run on a frontier model? If the answer is “most of them,” a routing audit is the highest-leverage exercise available.
- What is our cache hit rate, and is it semantic or exact-match? Below 25 percent semantically, there is room to move.
- Have we set output token caps on classification and extraction endpoints? A one-day fix worth running before any larger architectural review.
These are not gotcha questions. They are the same questions a good board already asks about cloud spend.
The compounding argument
The final reason to take this seriously now is structural. LLM costs scale with usage; usage scales with growth. Every month a company defers the audit is a month of compounding waste, and the gap between an unoptimized and optimized bill widens linearly with user count. The operators who did this work in month two of their product’s life have saved meaningfully more, in absolute dollars, than the operators who did it in month twelve even though both achieved the same percentage reduction.
According to Gartner’s forecast, AI services costs will, by the end of 2026, become a leading competitive factor in software margins, potentially overtaking raw model performance in importance. The companies that will win that competition are the ones that match model to task, instrument before they scale, and treat token efficiency as a first-class engineering concern rather than a year-end cleanup.
The bill is more fixable than it looks. The work just has to start before the next billing cycle.
Sources and further reading
- Ari Vance, “How I Cut My LLM Costs by 80% Without Sacrificing Quality,” Towards AI, March 2026.
- Ong et al., “RouteLLM: Learning to Route LLMs with Preference Data,” ICLR 2025.
- Jiang et al., “LLMLingua-2: Data Distillation for Efficient and Faithful Task-Agnostic Prompt Compression,” Microsoft Research, 2024.
- VentureBeat enterprise case studies on semantic caching, 2025.
- Gartner AI services cost forecast, 2026.
- OpenAI and Anthropic public pricing documentation, accessed Q2 2026.