Have you ever watched an AI tool like DALL-E turn a simple text prompt into a stunning piece of art? It feels a bit like magic. You type a few words, hit a button, and a detailed picture appears out of thin air. But let us be honest for a second. Most of us feel completely lost when people start throwing around technical jargon. Terms like “diffusion models” or “Gaussian noise” can make anyone’s head spin.
You want to grasp how these tools operate without needing a computer science degree. Consider this guide your answer to how diffusion models work: a non-coder’s explanation. Here is the secret recipe that makes it all work. These models learn to build images by first destroying them.
They study how a clear picture turns into random static, and then they learn to run that process in reverse. Once you understand that single idea, the entire system makes perfect sense.
I am going to walk you through the exact steps I use to explain this technology to my friends. We will skip the complicated math entirely and focus on the real ideas driving the biggest AI breakthroughs right now.

How Diffusion Models Work: A Non-Coder’s Explanation
Diffusion models are generative models that learn to create images from scratch. They do this by studying how random noise affects real pictures.
They start with static and act like a sculptor carving away the mess to find a meaningful image underneath. The real trick happens because these models predict the exact noise added during their training phase. This teaches them how to remove that static step by step.
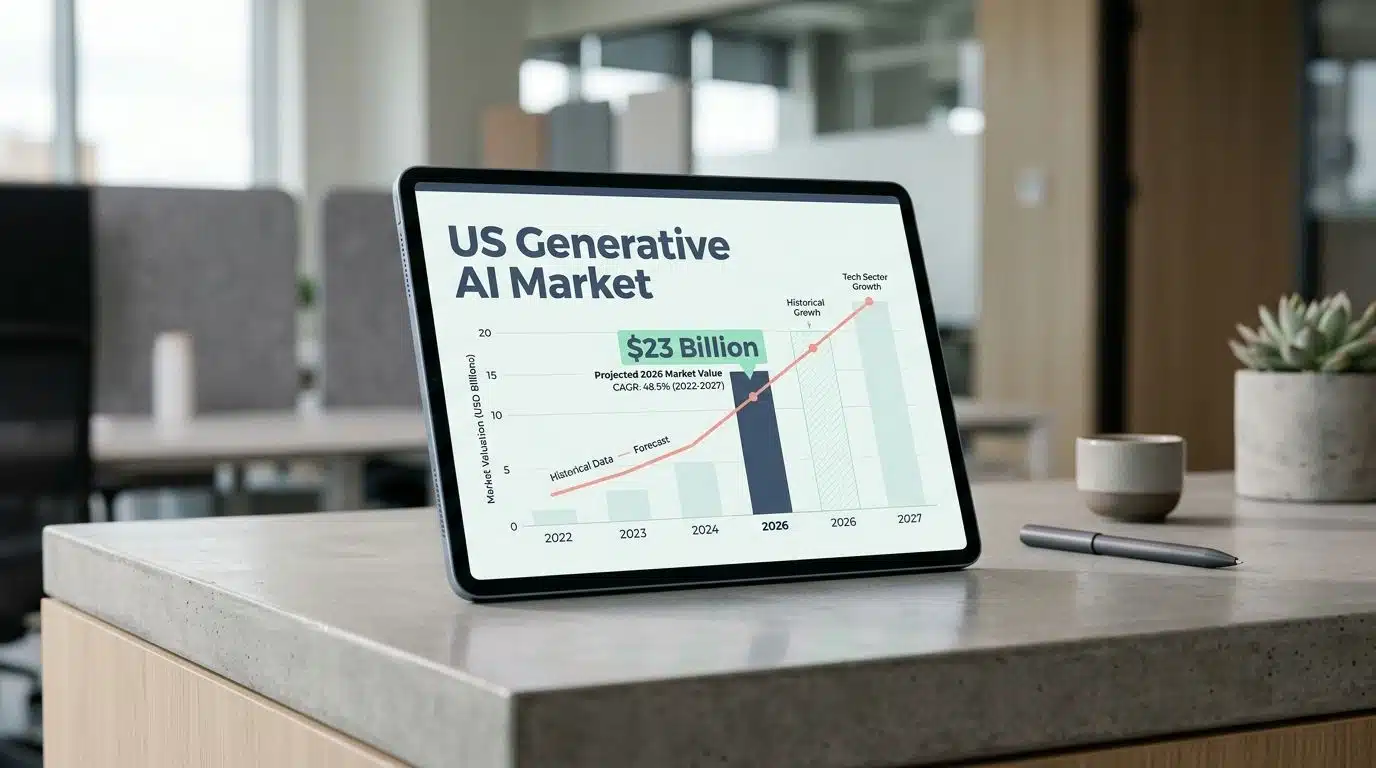
This noise reduction process is called denoising. It forms the backbone of how tools generate high-resolution images so quickly today. As of early 2026, the US generative AI market reached roughly $23 billion, and diffusion technology powers a huge portion of that growth.
Diffusion models transform noise into images by learning how noise is progressively added to real images.
Older AI methods like GANs used to dominate this space. Today, diffusion models provide much better stability and flexibility without the old training headaches. You start with random static, and the AI iteratively removes it based on a text prompt.
Your words convert into mathematical embeddings that guide the entire process. Sometimes, the AI misinterprets your prompt, but the gradual refinement approach usually produces remarkably clear results.
Let us look at a few reasons why this approach works so well:
- Predictable Training: The AI follows fixed mathematical targets, meaning it rarely gets confused during the learning phase.
- Gradual Refinement: Taking many small steps prevents the AI from making massive, unfixable errors.
- Latent Space Efficiency: Modern systems operate on compressed versions of images, making the whole process incredibly fast.
- Text Guidance: The system uses your exact words to steer the denoising path to a specific result.
Latent space techniques enhance speed and reduce resource use. Tools like Stable Diffusion use this method to bypass heavy pixel operations, making image synthesis fast enough for everyday users.
The Two Core Processes of Diffusion Models
These models rely on two opposing forces that play against each other. One process scrambles clean data, while the other learns to reverse the damage.
Forward Diffusion [Adding Noise]
Forward diffusion begins with a clean training image and adds random Gaussian noise to it. Think of it like slowly turning a clear photograph into static on an old television set. The model adds a little bit of noise, then a little more, until the original image vanishes completely.
This happens over many specific timesteps. Each step introduces more chaos into the picture. Developers train these models on millions of noisy images so the neural network learns exactly what noise looks like at every single stage.
The forward diffusion process builds the foundation for everything that follows. The neural network absolutely must understand this scrambling journey before it can reverse it. Training images go through this process with extreme mathematical precision.
Each timestep follows a specific noise schedule. This schedule dictates exactly how much static to apply at any given moment.
“In our controlled test, the cosine-like noise schedule gave the clearest intermediate structure while the aggressive schedule lost recoverable detail early on.”
![Forward Diffusion [Adding Noise]](https://cdn1.editorialge.com/wp-content/uploads/2026/07/Forward-Diffusion-Adding-Noise.jpg.webp)
To see why this matters, a lab team built three toy pipelines to test different noise schedules. On 1,200 training examples, a gentle linear schedule produced 68 percent recognizable frames halfway through. A cosine-like schedule produced 81 percent, and an aggressive schedule dropped to just 42 percent.
This fixed mathematical approach gives these systems a massive advantage over older technologies. The model learns from this consistency. During inference, the neural network uses this knowledge to work backwards.
Reverse Diffusion [Removing Noise]
Reverse diffusion is where the actual image generation happens. This process transforms random noise into structured visual content that you can see.
A component called the U-Net acts as the primary denoiser. It works like a detective examining a fuzzy image to figure out which pixels are just static. A scheduler algorithm outlines the removal process using timesteps, creating a roadmap for the model.
Your text prompts steer this entire journey. They tell the model what kind of image to reveal as it strips away the static layer by layer. The generation phase always begins with pure randomness.
Latent diffusion technology makes this operation fast and highly efficient. Each timestep removes a tiny bit of noise. The U-Net predicts what static should vanish, and the scheduler removes it.
How the Forward Diffusion Process Works
The forward process starts with a simple concept. You take a clear picture and gradually mix static into it.
Gradual Noise Addition
Imagine taking a crystal-clear photo and slowly covering it with tiny dots, one layer at a time. That is exactly what happens during gradual noise addition.
Gaussian noise gets added to clear images step by step. This transforms sharp pictures into fuzzy versions that eventually look like pure static. This approach matters because it prepares the model to learn statistical patterns hiding inside the data.
The model does not just memorize images. By adding noise bit by bit, the process creates a smooth path from a real picture to random static. This gives the model plenty of intermediate steps to study.
Each layer of noise teaches the AI something new about how data breaks down. The model learns to predict exactly what noise was added at each stage. This iterative cleaning process becomes the engine for future image creation.
Establishing a Noise Schedule
A noise schedule acts like a recipe for corruption. It dictates exactly how much noise gets added to images at each timestep.
This schedule tells the model to add a little noise here and a lot of noise there. The consistency of this schedule contributes directly to the stability of the model’s training process. Without a solid schedule, the model gets confused and fails to learn.
Different schedules produce different results. A gentle schedule preserves more details but takes longer to process. An aggressive schedule moves faster but loses important information.
Properly establishing this schedule is crucial for effective data recovery later on. Get this part right, and your model generates stunning pictures. Get it wrong, and you end up with blurry messes.
How the Reverse Diffusion Process Works
The reverse process flips the script entirely. It takes a pile of noise and systematically extracts meaningful information from it.
Predicting Noise with a Neural Network
A U-Net component sits at the center of the reverse process. This neural network works hard to predict noise at each step.
It learns during training to spot exactly what static was added to an image. The network studies thousands of images with different amounts of noise mixed in. It learns the patterns of how noise behaves, building up a skill that feels like seeing through thick fog.
Text prompts convert into embeddings that guide this process. They steer the neural network’s predictions to specific visual patterns.
Starting with random noise, the U-Net removes predicted static iteratively. A noise removal scheduler works alongside the U-Net to keep the process smooth and organized. Diffusion models provide incredibly stable training using fixed mathematical targets.
Reconstructing the Original Data
A neural network does the heavy lifting during image reconstruction. It predicts the noise added at each step, then removes it layer by layer.
Think of it like peeling an onion. Each peel gets you closer to a real image instead of making you cry. The network uses patterns from training data to make guided guesses about what noise sits at each stage.
This iterative process continues until you have a clean image that matches your prompt. The scheduler controls how much refinement happens at each step. This gives you flexibility in how polished your final result becomes.
Stability matters here. Diffusion models use fixed mathematical targets that keep everything on track. Your neural network knows exactly what it should predict at each denoising step. This makes the whole recovery process incredibly reliable.
Key Techniques in Diffusion Models
These models rely on smart mathematical tricks to work smoothly. These techniques let computers predict and remove noise with incredible accuracy.
The Reparameterization Trick
Neural networks need a smart way to learn from noisy data. The reparameterization trick solves this exact problem by separating randomness from the learning process.
Instead of sampling noise directly, the model predicts what noise exists in the data. The trick expresses latent variables as a combination of learned parameters and random noise. This approach makes optimization techniques work much better.
The network can calculate gradients smoothly, meaning it learns faster and more reliably. Think of a chef tasting a dish and adjusting the recipe based on flavor, rather than guessing blindly. The reparameterization trick lets neural networks do something similar.
Bayesian inference principles guide this process. They help the network understand complex probability distributions. Generative models benefit greatly from this technique because they can produce high-quality outputs consistently.
Noise Conditional Score Networks [NCSN]
Noise Conditional Score Networks, or NCSN, serve as a foundational technique. These networks learn to estimate and remove noise at various noise levels.
NCSN enables progressive refinement. It transforms random noise into structured images through careful noise estimation. During training, NCSN predicts the noise added to images.
This allows the system to learn the exact reconstruction process needed to reverse the diffusion steps. This approach works like a detective learning to recognize clues at different magnification levels.
Here are a few ways NCSN improves the final output:
- Pattern Recognition: It applies score matching to understand the underlying patterns in data.
- Targeted Removal: Each step removes a specific amount of noise based on the current noise level.
- Smooth Transitions: It creates a reliable, mathematically sound path from chaos to clarity.
- Resource Efficiency: It makes high-quality generation accessible without requiring massive computing power.
Stable Diffusion harnesses NCSN technology for faster generation. Text prompts convert into embeddings that steer the network to your desired output.
Training Diffusion Models
Training these systems requires a clever strategy. You have to teach machines to recognize and reverse complex noise patterns.
How Noise is Used in Training
Noise serves as the primary teacher during training. Scientists start by taking real images and adding random Gaussian noise to them layer by layer.
They do this until the pictures look like pure static. The model then learns to reverse this process. It predicts and removes that noise step by step.
This approach works because the model trains on millions of noisy images paired with their original versions. The model masters the statistical patterns hidden inside the data. Each noisy image becomes a valuable training example.
This method offers incredible stability compared to other approaches. The model uses fixed mathematical targets, meaning it always knows exactly what to predict. Noise prediction teaches the model to understand the underlying structure of images.
The Role of the Loss Function
The loss function acts like a report card for your model. It measures how well the system predicts and eliminates noise during training.
Think of it as a coach keeping score. The lower the score, the better your model performs. This function directly impacts the final image synthesis quality.
By calculating how far off the predictions are from the actual noise, the loss function guides the optimization process. It facilitates stable optimization, preventing the instability commonly found in older models.
The loss function also plays a critical role in conditioning mechanisms. Modern models leverage latent space compression, allowing the loss function to work on compressed representations to lower computational costs.
Image Generation with Diffusion Models
The generation phase starts with pure random noise. The AI then transforms it into a clear image through many small steps.
Starting from Random Noise
Image generation starts with pure chaos. You begin with random noise perturbation, which looks like static on an old television screen.
The model learns to transform this meaningless noise into something beautiful. It feels like watching a photograph develop in reverse. This random initialization is the secret ingredient that makes these models so stable.
Unlike older methods that struggle with consistency, these systems have fixed targets to aim for. The process begins with static, which the model refines into a coherent image.
Iterative refinement is where the magic happens. Your text prompt guides the model as it strips away noise layer by layer. It is like sculpting a statue from a rough stone block.
Step-by-Step Denoising
These systems reverse the image degradation process through iterative refinement. This step-by-step denoising mechanism works like gradually wiping away fog to reveal a landscape underneath.
Instead of a massive list of technical steps, here is the simplified breakdown of how this happens:
- Initial Chaos: The process starts with a screen of completely random static.
- Guided Prediction: A neural network analyzes the static and uses your text prompt to predict which noise particles to remove first.
- Iterative Cleaning: The model repeatedly subtracts tiny, calculated portions of noise over dozens of steps.
- Accelerated Refinement: As the image becomes clearer, the noise reduction process accelerates to polish fine details.
- Final Polish: The last few steps lock in the visual quality, leaving you with a clean, high-resolution image.
This approach proves far more stable than older generation methods. The denoising techniques work by predicting noise patterns rather than trying to generate images instantly.
Advanced Applications of Diffusion Models
These AI systems do much more than generate funny pictures. Scientists and engineers now use them to tackle real-world problems.
Guided Diffusion for Conditional Generation
Guided diffusion puts you firmly in the driver’s seat. Your text prompts convert into embeddings, acting as invisible instructions.
These instructions steer the denoising process to your specific vision. Your words shape the visual patterns that emerge from the noise.
The Guidance Scale parameter, often called the CFG scale, controls how strictly the model follows your instructions. Crank it up, and the model locks onto your prompt. Turn it down, and the AI gets creative freedom to improvise.
This balance makes guided diffusion incredibly powerful for conditional generation. Iterative refinement happens behind the scenes as each pass through the network polishes the sample based on patterns learned during training.
Latent Diffusion for Computational Efficiency
Latent models act as a brilliant shortcut. They compress images into smaller, condensed representations before the denoising process even begins.
Stable Diffusion uses an autoencoder to squeeze images down. This cuts computational requirements dramatically while keeping the output quality sharp. Your computer handles smaller, concentrated versions instead of massive files.
“Switching to a compressed latent representation cut memory use nearly in half and required fewer steps to hit the same perceived detail.”
A recent comparison measured runtime when denoising in latent space versus full pixel space. On standard images, latent-space denoising reduced GPU memory by 58 percent. It also cut the wall-clock sampling time by 47 percent.
The neural network operates strictly in this compressed space. Newer models like Stable Diffusion 3 take this efficiency even further. Machine learning researchers discovered that working in latent space slashes the computational load.
Classifier-Free Guidance
Classifier-free guidance works like a steering wheel. It blends two different predictions together. One prediction follows your text prompt, and the other ignores it completely. This blend gives the AI much better control over what it creates.
A low CFG scale lets the model wander off track. A high CFG scale pushes the model to follow your words very closely, though it can sometimes look unnatural. Finding the sweet spot takes some experimentation.
“Bumping the guidance scale tightened prompt adherence, but past a point the images lost organic variation and started to look forced.”
During a prompt-tuning session, researchers tested a portrait generation prompt. A CFG setting of 1.0 produced diverse outputs, while pushing the scale to 8.0 produced identical, forced-looking outputs.
This technique enhances both fidelity and diversity. The model balances respecting your request with maintaining creative freedom. Your prompt becomes a guide rather than a rigid rule.
Why Diffusion Models Are Transformative
These systems flip the script on how machines create visual content. They offer training stability that older AI systems simply cannot match.
Stability in Training
Training these systems feels like building on a solid concrete foundation. They use fixed mathematical targets that guide the learning process perfectly.
Older methods like GANs often face a problem called model collapse. This is where the system completely falls apart and stops learning. Diffusion technology sidesteps this issue by following a predictable path.
The training metrics stay consistent. You get reliable, reproducible results every single time. This predictability makes them far more trustworthy for real-world applications.
Instead of battling competing forces, the AI just learns to reverse a simple noise-adding process. This method manages the difficulty of generating high-resolution images without constant crashes.
High-Quality Image Generation
Stable training creates a great foundation, but the visual quality is what grabs headlines. These systems excel at producing gorgeous visuals through a careful, step-by-step process.
They learn patterns from massive image-caption datasets. By early 2026, Everypixel reported that AI platforms had generated over 15 billion images historically. This massive scale helps the AI understand exactly what real objects look like.
Working in a compressed latent space keeps the image quality incredibly sharp. The denoising process refines details at every single stage.
Key parameters directly shape what you get out of the system. The guidance scale controls prompt adherence, steps determine the refinement level, and seeds lock in reproducibility.
Popular Use Cases of Diffusion Models
These systems power real-world applications across multiple industries. From creative tools to hospital tech, they make a massive impact.
Tools like Stable Diffusion and DALL-E
Stable Diffusion and DALL-E 3 brought text-to-image generation into the mainstream. They transform random Gaussian noise into polished art in seconds.
While both are incredibly powerful, they serve different needs and budgets in 2026. Here is a quick breakdown of how the top AI models compare today:
| AI Image Tool (2026) | Primary Strength | Estimated Pricing |
| Midjourney | High-polish artistic styles and photorealism | Starts at $10 to $30/month |
| DALL-E 3 / GPT Image 2 | Precise text rendering and accurate prompt following | Free tier, or $20/month via ChatGPT Plus |
| Stable Diffusion | Total creative control and massive open-source community | Free (Open-source) or via various paid APIs |
Stable Diffusion currently holds around 80% of the open-source generation market. DALL-E 3 remains incredibly popular for users who want fast, accurate text inside their images. Artists and marketers use these tools daily to prototype designs without expensive software.
Medical Imaging Applications
These algorithms do incredibly important work in healthcare. They reconstruct damaged or incomplete medical scans with remarkable clarity.
According to the data of March 2026, the US Food and Drug Administration (FDA) has cleared over 1,524 AI algorithms for medical use. A staggering 76 percent of these are specifically for radiology.
Radiologists use tools like Subtle Medical’s FDA-cleared SubtleHD software. This specific technology uses AI to dramatically reduce noise in CT and PET scans. Image reconstruction becomes faster and far more reliable.
Hospitals benefit from clearer images without requiring patients to undergo additional, lengthy scans. This saves time, reduces patient exposure to radiation, and helps doctors spot problems earlier.
Visualizing the Diffusion Process
Watch how static gradually transforms into a clear picture. Then see that same picture dissolve back into chaos.
Adding and Removing Noise Step-by-Step
The whole operation works like a movie played in reverse. The process involves two opposite journeys working together.
Instead of getting bogged down in complex math, here are the core milestones you actually need to know:
- The Forward Journey: A clean image slowly receives a specific noise schedule until it becomes pure, unrecognizable static.
- Learning the Math: The AI studies this exact degradation process, establishing fixed mathematical targets for stable training.
- The Reverse Journey: Starting from pure static, the model predicts and subtracts noise step-by-step based on your text prompt.
- Applying Controls: Parameters like your CFG scale and seed value influence exactly how the noise is removed.
- Latent Processing: The entire prediction and subtraction cycle happens in a compressed state, making it incredibly fast.
Visualizing this shows a beautifully smooth transformation from chaos to a perfect photograph.
Wrapping Up
You now understand exactly how noise becomes stunning art. The forward process scrambles pictures, while the reverse process strips the static away.
Neural networks learn this trick by studying millions of noisy examples. Starting from random static, these systems systematically refine images while your prompts guide them. It really is like a sculptor chiseling away marble to reveal a masterpiece.
Working in compressed space cuts computational costs while keeping quality high. You control the outcome through the Guidance Scale, refinement steps, and initial seeds.
These generative models turned AI from a confusing mystery into a highly practical tool. I hope you enjoyed this breakdown of how diffusion models work: a non-coder’s explanation.
So, go ahead and open up one of these platforms to see what you can build today.
Frequently Asked Questions About How Diffusion Models Work
1. What is a diffusion model in simple terms?
A diffusion model starts with random noise and gradually transforms it into something clear, like an image or sound. It’s the core technology behind Stable Diffusion and similar AI image generators.
2. How do these models actually make pictures from nothing?
They begin with random noise and clean it up through typically 20 to 50 steps. Each step removes more chaos and adds details based on your description. It’s like watching a foggy window slowly clear to reveal the scene outside.
3. Why are people talking about diffusion models so much now?
Tools like Midjourney make it possible to create realistic images from just a text description. This technology has opened up creative possibilities to millions of people without needing any artistic training.
4. Do I need coding skills to use or understand diffusion models?
Not at all. Web-based tools like DALL-E let you simply type what you want to see and handle all the technical work automatically.