Agent Memory and Context used to sound like a fancy way of saying, “Let’s keep the chat history.” That was fine when AI agents were simple assistants answering one question at a time. But in 2026, that definition feels painfully outdated. The best teams I study and work around do not treat agent memory as a bigger notepad. They treat it like infrastructure. That is the real shift.
A serious AI agent now has to remember the user, follow a task across many steps, call tools, read files, manage permissions, avoid stale information, and sometimes continue work across sessions. If all of that goes into one giant prompt, the agent eventually becomes slow, expensive, confused, or unsafe.
That is why Agent Memory and Context has become one of the most important topics in AI engineering. The best teams are not just asking, “How much context can the model take?” They are asking, “What should the model see right now, what should stay outside the prompt, and what should never be trusted blindly?” That difference matters.
In this guide, I’ll walk you through the memory layers, the system parts that matter, and the practical patterns top teams use to keep interaction history useful without letting context management spiral out of control.

Context, State, and Memory Are Not The Same Thing
This is the part I always like to separate early, because many bad agent systems fail right here.
- Context: is what the model sees in the current call.
- State: is what the system tracks while the task is running.
- Memory: is what the agent can reuse later.
They overlap, but they are not the same.
Here is the simple version:
| Concept | What It Means | Example |
| Context | The information sent to the model right now | Current user request, selected memory, recent tool result |
| State | The live task record outside the model | Current step, selected plan, pending approval, user ID |
| Memory | Information saved for future use | User preferences, project rules, past successful patterns |
This distinction is not just theory. LangGraph’s memory model separates short-term memory from long-term memory. It also describes semantic memory for facts, episodic memory for past experiences, and procedural memory for instructions or rules.
That is a much healthier way to think about agent design. When everything is treated as “context,” the prompt becomes the database. That is a bad idea. Prompts are not built to be reliable databases. They are temporary working surfaces.
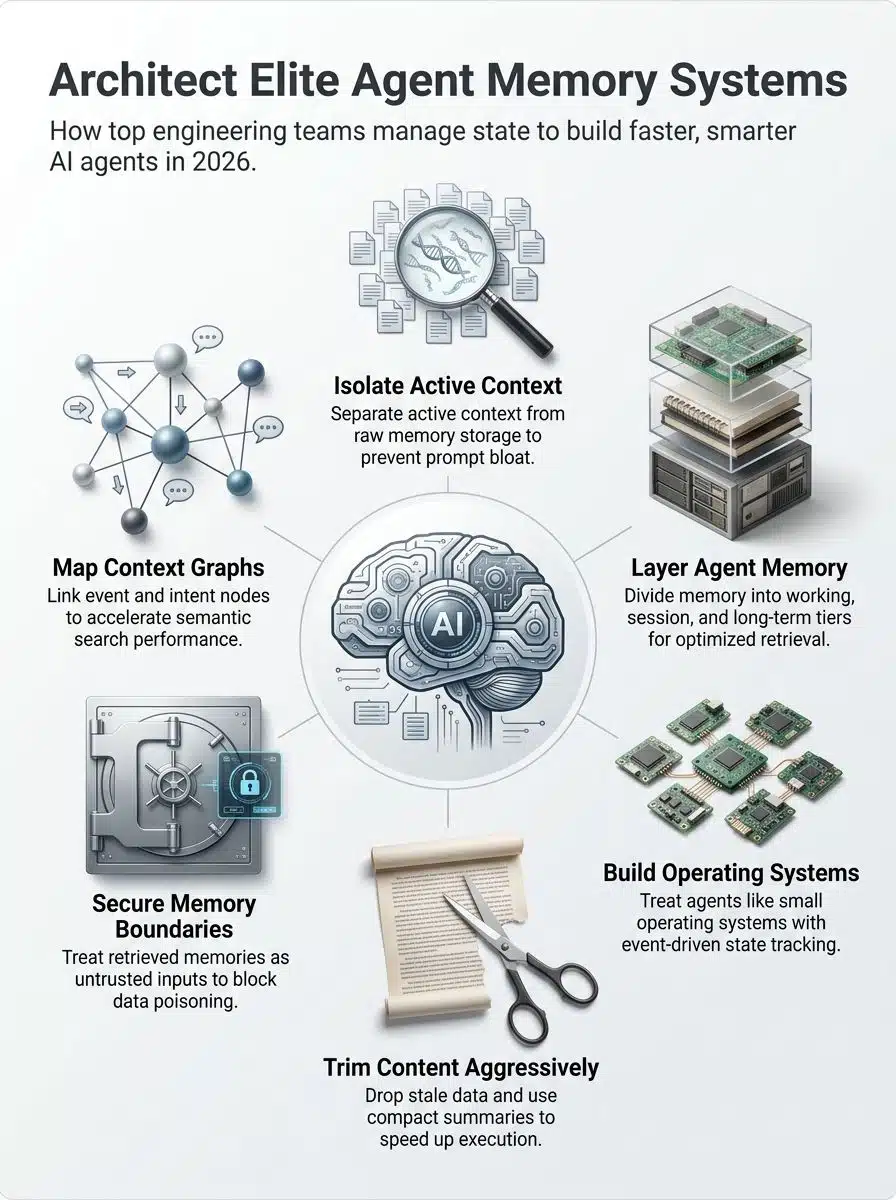
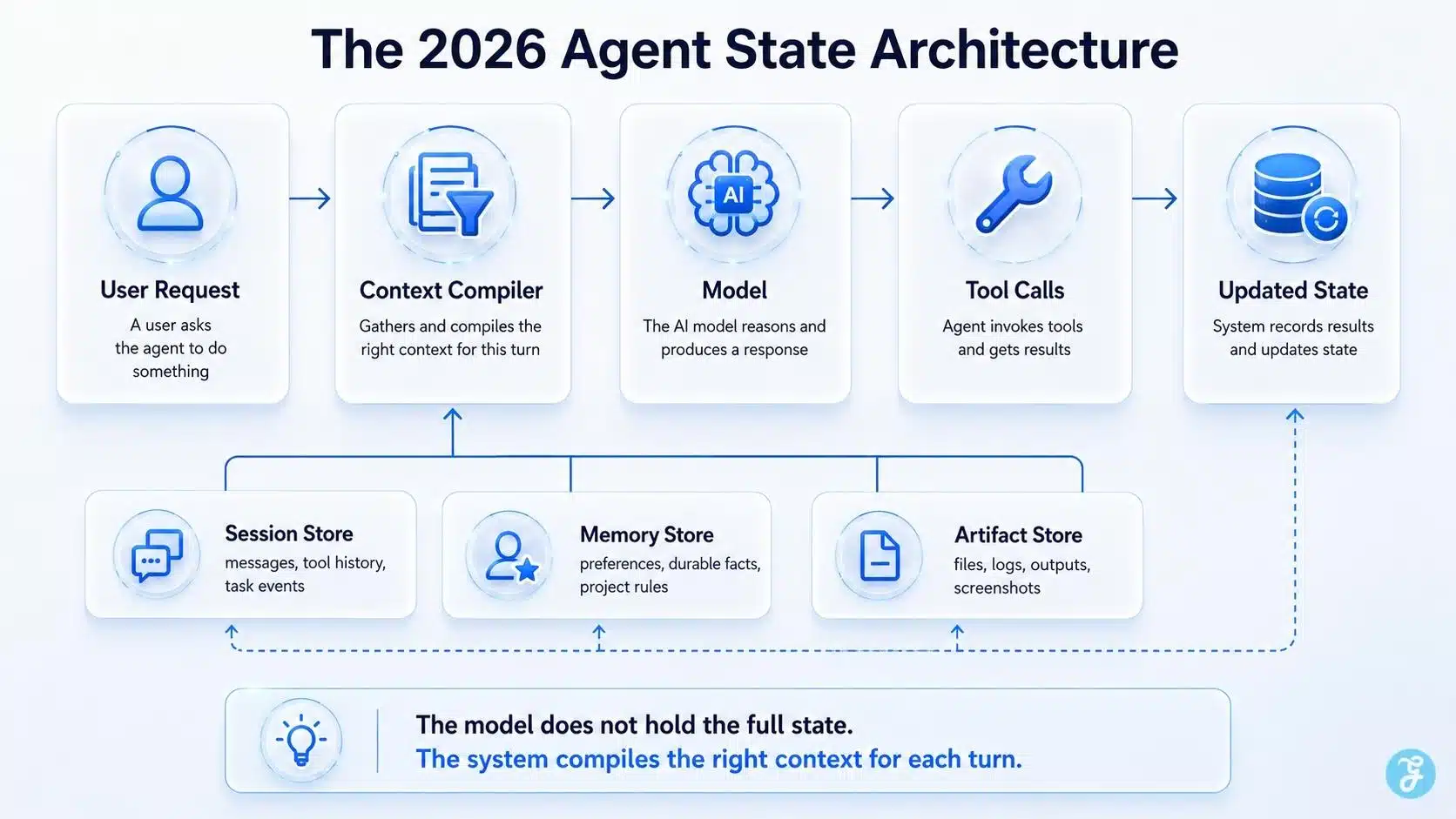
Defining Memory and Context in AI Agents
If you want a simple rule, use this one: memory is stored state, context is the slice of state the model sees right now. That sounds small, but it changes everything. Once you separate those two ideas, you can stop treating the prompt like a junk drawer.
Defining agent memory
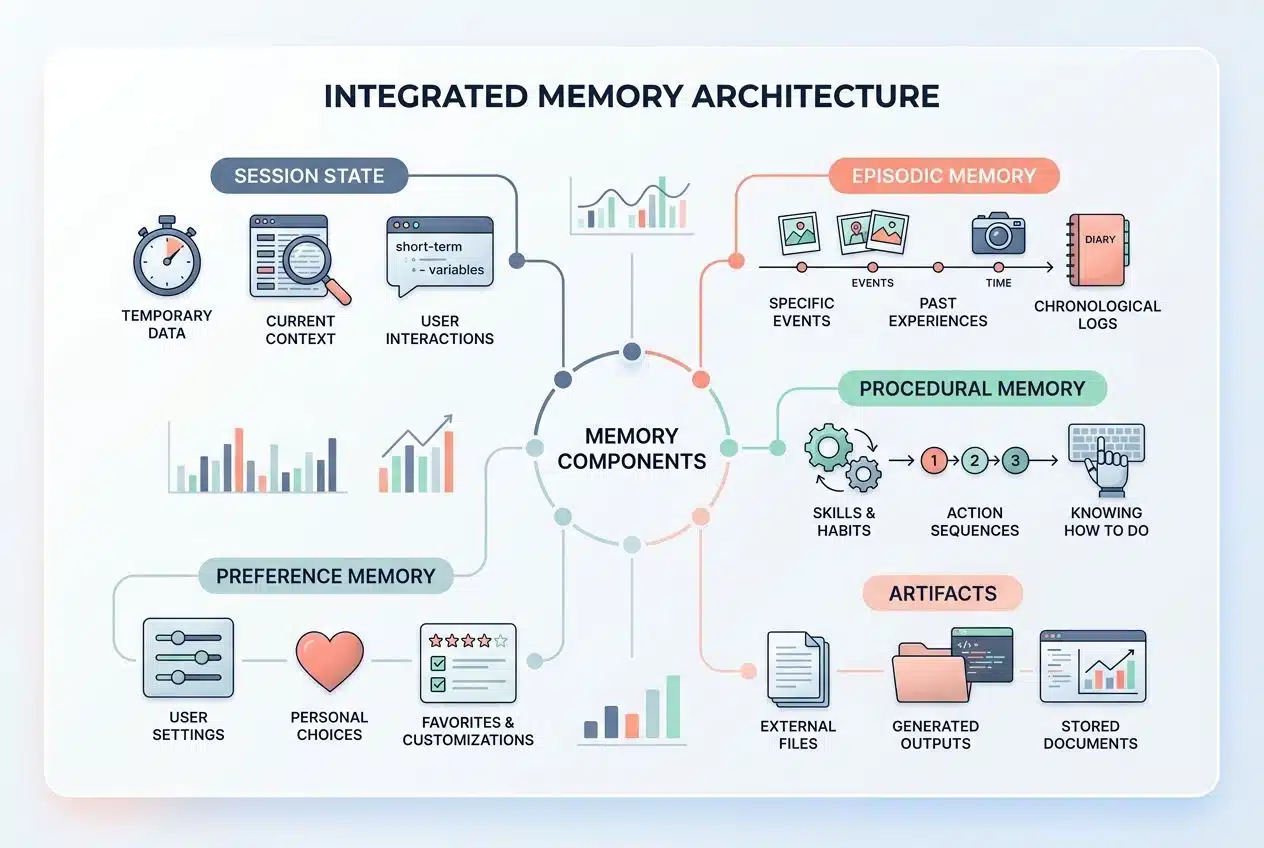
Agent memory stores facts, preferences, prior actions, tool outputs, and artifacts that may matter later. Good memory architecture also stores provenance, which means where a fact came from and when it was written, so old notes do not quietly outrank fresh instructions.
As of 2026, LangGraph documents two distinct layers out of the box: short-term memory inside agent state for multi-turn work, and long-term memory across sessions. That split is a practical reminder that working memory and knowledge retention should not live in the same bucket.
- Working context: the small packet the model sees this turn.
- Session state: task status, recent decisions, and current goals.
- Long-term memory: stable facts that should survive across sessions.
- Episodic memory: what happened in a specific run, ticket, or case.
- Procedural memory: repeatable rules, playbooks, and business logic.
- Artifacts: files, code, documents, spreadsheets, and generated outputs.
Good memory is not one file, it is a filing system.
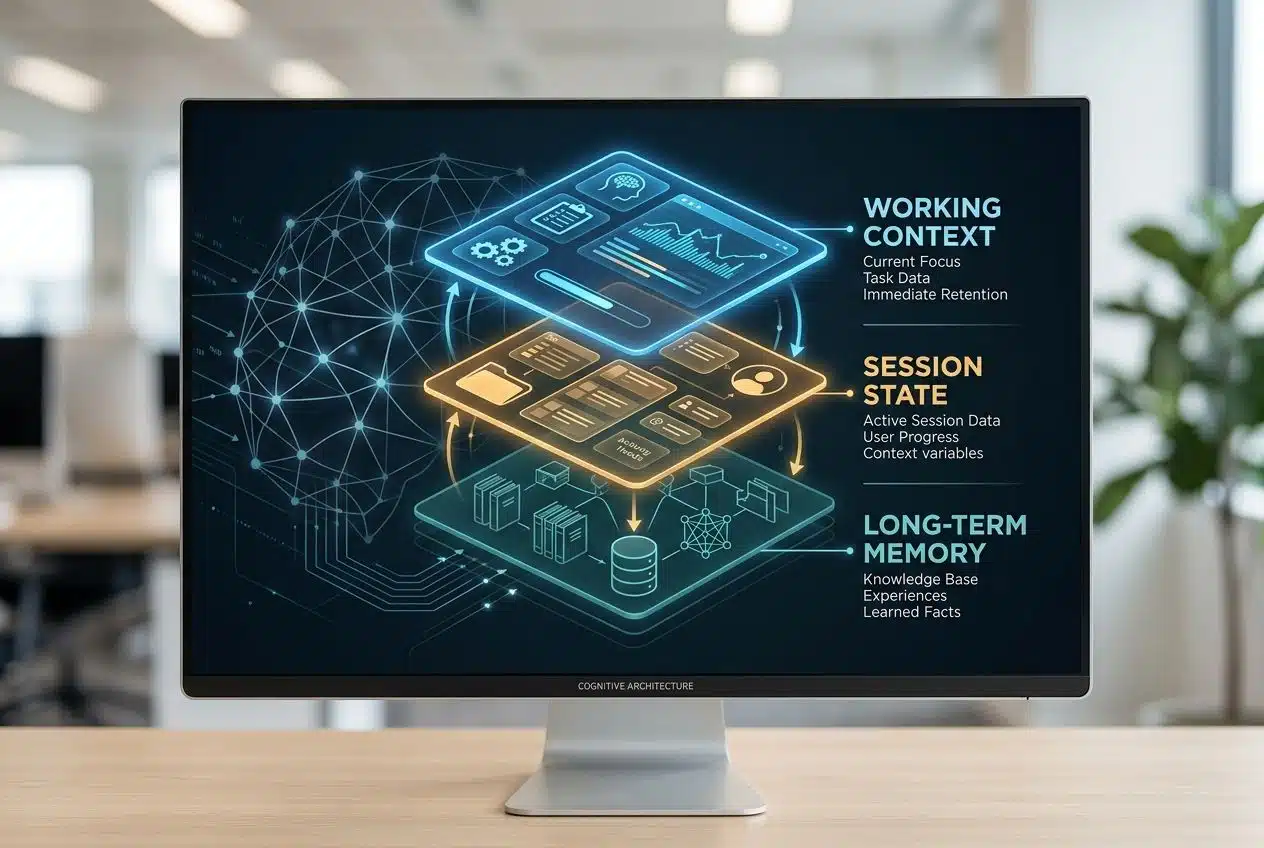
Understanding context as dynamic and situational
Context is the temporary view the agent uses to make the next decision. It should pull in only what helps right now: recent turns, the current task, the next tool result, the right user preference, and any policy the agent must follow.
OpenAI’s Agents SDK uses this idea directly. It starts a run with a small memory summary of useful tips, preferences, and available memories, then lets the agent read deeper only if it needs to.
That is why large context windows do not remove the need for state management. Bigger windows help, but they do not decide what is relevant, what is stale, or what should never be written back into memory.
The Importance of State Management in AI Agents
State management is what keeps an agent coherent over time. It tells the system what happened, what changed, what still matters, and what the agent is allowed to do next. Without it, experience retention turns into transcript replay. That is expensive, noisy, and fragile.
Enhancing agent performance through state retention
Good teams retain state in structured fields, not just in chat text. They track things like task status, tool results, approval state, user preferences, and artifact locations, then compile only the pieces that matter into working memory.
Google ADK makes this operational. Its session docs say state updates should happen as part of appending an event to session history, which keeps persistence and thread safety aligned instead of letting random code paths mutate state in the dark.
That event-first pattern pays off when you debug failures. You can see what the agent knew, when it knew it, and which event changed the plan.
- Store decisions: capture chosen options, not every chain of thought.
- Store status: keep task phase, blockers, owners, and deadlines in fields.
- Store references: point to artifacts instead of pasting huge blobs into prompts.
- Store permissions: keep role and access scope outside free-form notes.
- Store freshness: attach timestamps so new facts can beat old ones.
Keep the state clean, and the agent behaves.
Balancing short-term and long-term memory
Short-term memory should help the agent finish the task in front of it. Long-term memory should help it avoid repeating stable facts later. Do not mix those goals. A temporary shipping exception, a one-off refund, or a tool error should rarely become permanent memory.
In practice, the safest pattern is simple: write session state often, write long-term memory sparingly, and require stronger checks before anything becomes persistent. That one rule cuts drift, lowers contamination risk, and improves AI agent performance over long workflows.
How OpenAI, LangGraph, Google ADK, and Claude Code Handle State
Different platforms handle memory differently, but the trend is clear. Everyone is moving away from raw prompt stuffing.
OpenAI’s current agent guidance talks about managing what is stored, recalled, and injected into the model’s working memory. Its personalization cookbook shows a state-based pattern: use a structured state object, distill session notes, consolidate global notes, and inject selected state with precedence rules.
That word “precedence” matters. Current user instructions should beat the old memory. Session-specific instruction should beat general preference. Otherwise, memory becomes annoying or dangerous.
LangGraph separates short-term thread memory from long-term memory saved across sessions. It also encourages teams to think clearly about semantic, episodic, and procedural memory.
Google ADK separates session, state, memory, and artifacts. Its context engineering guidance treats context as a compiled system, not a growing text file.
Claude Code gives another useful example. Each session starts with a fresh context window, but knowledge can carry across sessions through CLAUDE.md files and auto memory. Claude Code’s docs also explain that subagents can handle research in their own separate context window, so the main context is not flooded with large file reads.
That is the pattern to notice. The model may be powerful, but the best teams are building memory boundaries around it.
Components of Effective Agent Memory
Effective memory architecture is a stack, not a feature toggle. Each layer should have a clear write path, a retrieval path, and a reason to exist.
Pre-trained data and external knowledge sources
Pre-trained model knowledge gives the agent broad language skills and general facts. It does not give you current policy, customer-specific details, or reliable internal knowledge retention.
That is where external sources matter. A vector store can help with semantic recall, but it works best when you pair it with metadata like user, workspace, product area, confidence level, and freshness.
Pinecone’s current indexing docs describe metadata as automatically indexed for filtering, which matters because raw similarity search alone often pulls the right topic from the wrong customer or the wrong date.
Session-based memory
Session-based memory is your active case file. It should include recent interaction history, the current plan, important tool results, and the artifacts the agent may need to revisit during the same job.
The most useful detail is identity. In the OpenAI Agents SDK, stable conversation or session IDs are what let separate runs share one memory conversation instead of acting like isolated turns.
If you skip stable IDs, you lose continuity even when your memory tools are working perfectly. Teams often blame retrieval when the real problem is broken session identity.
Persistent memory for long-term learning
Persistent memory is where teams get the biggest upside and the biggest risk. It can hold user preferences, reusable procedures, durable facts, and important patterns from past work, but it can also preserve mistakes for weeks if you write carelessly.
| Memory component | Best use | What to avoid |
|---|---|---|
| Session state | Current task progress, recent tool outputs, approvals | Keeping it forever |
| Episodic memory | Past cases, project milestones, outcome summaries | Writing every turn |
| Procedural memory | Playbooks, escalation rules, business constraints | Letting user chatter overwrite policy |
| Preference memory | Stable user choices, format preferences, recurring settings | Saving guesses as facts |
| Artifacts | Files, drafts, code patches, reports, spreadsheets | Pasting large files back into prompts |
A good write rule is strict: if a fact changes often, stays local to one task, or has low confidence, keep it in session state or an artifact, not in permanent memory. That is how teams protect experience-building from turning into experience hoarding.
Context Engineering for AI Agents
Context engineering is the craft of building the right prompt at the right moment from a much larger state system. It is where cost control, speed, and answer quality finally meet.
Context trimming techniques
In Anthropic’s April 2026 engineering post on Managed Agents, the company drew a sharp line between the session log and the model’s context window. That matters because it gives you a durable record outside the prompt, then lets the harness fetch only the right slice for the next step.
That same post recommends compaction and context trimming, including clearing old tool results and other bulky tokens that stop helping once a task moves on.
- Keep the working context small. Put active goals, the next action, and the minimum proof needed for that action at the top.
- Move raw logs out of the prompt. Store them in an event log and reference them by ID or artifact name.
- Trim after milestones. Once a step is complete, replace its long trace with a short verified summary.
- Separate rules from chatter. Put policies and permissions in structured fields so they do not get buried by conversation.
- Filter by scope. If a memory belongs to one user, team, or app, make that explicit before retrieval.
- Cache the stable prefix. Keep tool schemas, long instructions, and static background at the front, where caching can help.
A January 2026 study on long-horizon agentic tasks tested more than 500 agent sessions and found prompt caching cut API cost by 41% to 80% while improving time to first token by 13% to 31%. The same paper warned that naive full-context caching can raise latency when dynamic tool results keep changing, so teams get better results by caching the stable prefix and excluding volatile outputs.
Context summarization methods
Summaries should compress the past without hiding the parts that still drive decisions. A useful summary answers four questions: what changed, what is still true, what is blocked, and what evidence supports that status.
- Write structured summaries: use fields such as goal, status, blockers, open questions, and next action.
- Keep contradictions visible: if a new fact conflicts with an old one, log the conflict instead of silently replacing it.
- Attach provenance: save the source event, tool, or artifact that produced the summary.
- Prune on schedule: stale summaries should expire or get consolidated before they clutter retrieval.
Building context graphs
Context graphs help when the task depends on relationships, not just keywords. A graph can connect users, projects, tickets, files, decisions, and deadlines so the agent can ask, “Which artifact belongs to this project?” instead of running a blind similarity search.
You do not need a giant knowledge graph to get value. Start with a small set of node types, such as user, task, artifact, and policy, then store links like owns, depends on, supersedes, or generated.
This is especially useful for information routing. It lets your retrieval layer fetch the latest approved artifact, the right policy for the task, and the last successful action, all before the model starts reasoning.
Memory and Context Retrieval Strategies
The retrieval strategy is where many teams over-focus on vector search and miss the bigger picture. The best systems route requests to the cheapest, most reliable source first, then escalate only when needed.
Agentic search for relevant context
Agentic search works best when the agent knows what kind of answer it needs. Is it looking for the latest task status, a similar prior case, a policy rule, or a file it created earlier? Those are different retrieval jobs, and they should not all hit the same store.
Use the session log for recent truth, persistent memory for stable facts, a vector store for semantic recall, and artifacts for the full details. That is a better pattern than sending every question through the same dense-retrieval pipeline.
Leveraging vector databases for memory optimization
Vector databases are valuable because they search by meaning instead of exact wording. They become much more reliable when you add metadata filters for customer, workspace, document type, date, confidence, or sensitivity.

| Retrieval path | Best for | Main risk |
|---|---|---|
| Session log scan | Recent decisions and current task state | Gets expensive if you replay too much text |
| Vector search | Semantic recall across large knowledge stores | Near matches from the wrong scope |
| Artifact fetch | Files, reports, code, and full evidence | Stuffing too much raw content back into context |
| Graph lookup | Relationships between users, tasks, tools, and outputs | Weak schemas that leave links ambiguous |
In practical memory frameworks, this routing logic matters as much as the model. If you want higher contextual awareness, make the agent choose a retrieval path on purpose instead of treating memory as one giant search box.
Applications of Memory and Context in 2026
In 2026, good memory and context management show up anywhere an agent has to stay consistent for more than a few turns. That includes customer support, coding, research, operations, and collaborative intelligence inside team workflows.
Supporting long-horizon task execution
Long tasks break when the agent cannot resume cleanly. It forgets its last checkpoint, repeats tool calls, or loses the artifact it created twenty minutes ago.
Anthropic’s April 8, 2026, launch of Managed Agents put this issue front and center: long-running sessions can operate for hours and keep progress even through disconnections. OpenAI’s background mode solves a related problem from another angle by letting long jobs run asynchronously while your system polls for status instead of blocking a live request.
That means teams can move multi-step work, like document review, code changes, or meeting prep, out of brittle single-request loops and into resumable workflows.
Improving conversational continuity and personalization
Continuity is not about remembering everything. It is about remembering the few things that save the user from repeating themselves.
Preference memory is a good example. If a user always wants bullet summaries, metric units, or a certain ticket format, the agent should reuse that pattern without asking every time.
- Support agents keep account-specific preferences and recent issue context.
- Coding agents keep repo structure, prior fixes, and open implementation decisions.
- Research agents keep source queues, working hypotheses, and artifact lists.
- Project agents keep task owners, deadlines, blockers, and approval states.
That is why conversational continuity and personalization depend on good state management, not on a longer transcript. The agent should remember the right things, in the right place, for the right length of time.
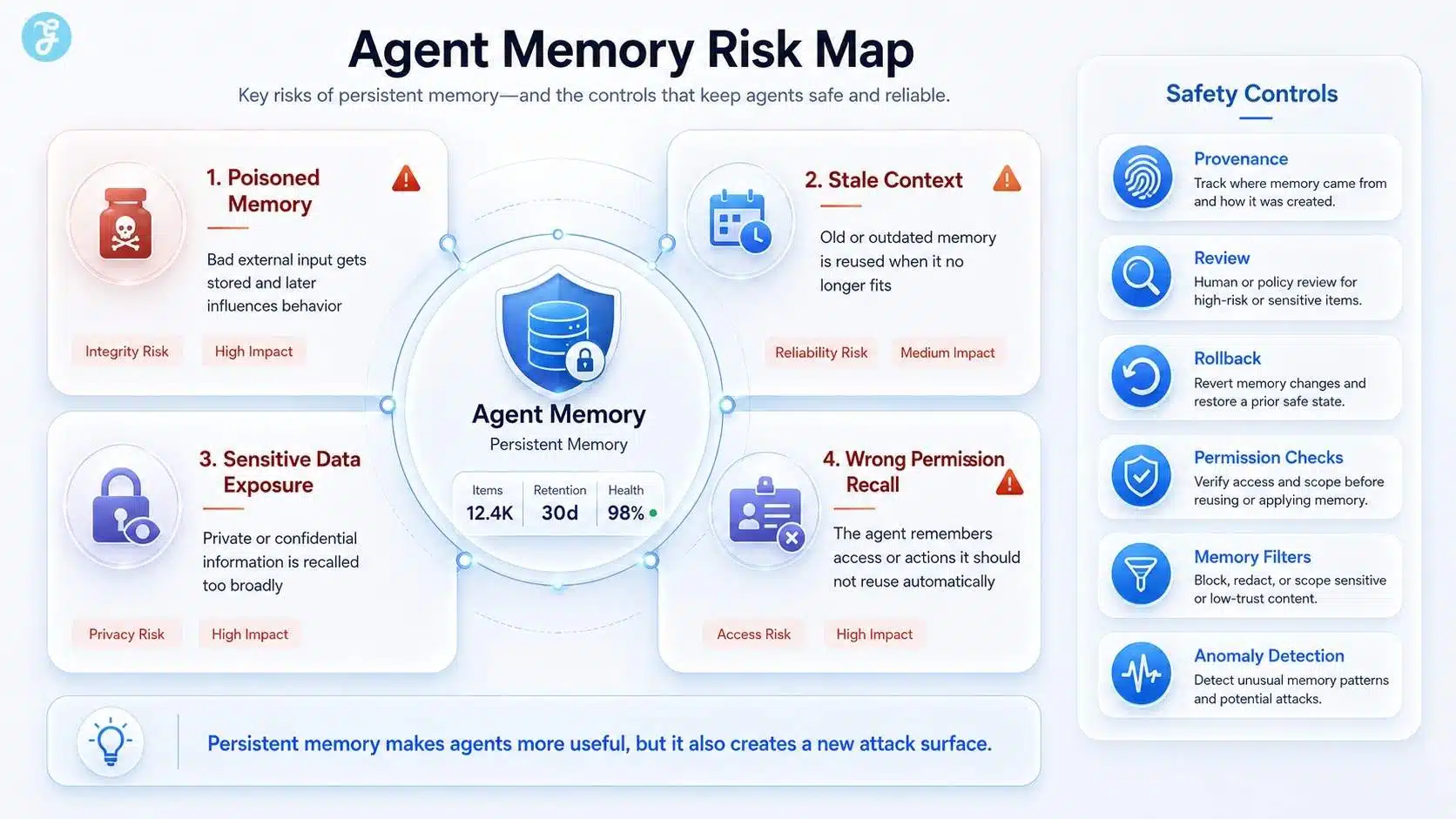
Challenges in Memory and Context Management
Memory sounds helpful until it starts preserving the wrong thing. Then it becomes a source of drift, privacy risk, and expensive noise.
Handling memory limitations in AI models
Large context windows help, but they do not solve interference. A May 2026 benchmark called MINTEval evaluated seven representative systems on contexts averaging 138.8k tokens, with some instances reaching 1.8 million tokens, and found an average accuracy of just 27.9%.
The lesson is simple: more tokens do not automatically produce better recall. Agents still struggle when facts get updated, contradicted, or buried under related details.
That is why teams use bounded memory, periodic consolidation, and conflict rules that prioritize fresh verified facts over old notes. If your agent handles long workflows, benchmarking memory behavior should be part of normal performance optimization, not a side task.
Addressing privacy and security concerns
Persistent memory is also an attack surface. AgentLAB, released in February 2026, introduced 644 security test cases across 28 realistic environments and included memory poisoning among the attack types it used to evaluate agents.
So your write path needs policy gates. Do not let a user message, web result, or tool output become durable memory without checks for trust, scope, and contradiction.
- Scope memory by owner: separate app, user, and session memory instead of blending them.
- Gate writes: require validation before durable memory changes.
- Encrypt checkpoints: protect saved state the same way you protect other sensitive records.
- Log provenance: track which tool, event, or person introduced a fact.
- Expire stale data: old memory is often more dangerous than missing memory.
Google ADK’s support for scoped keys, such as app-level and user-level state, is a good operational model here. It nudges teams to separate data by intent before they ever start retrieval.
The Future of Agent Memory and Context Handling
The future is moving away from transcript replay and toward managed state systems with clear logs, durable checkpoints, and tighter memory management rules. You can already see that pattern across AI frameworks from LangGraph, Google ADK, OpenAI, and Anthropic.
Emerging trends in memory architectures
One clear trend is the split between recoverable storage and runtime context. Teams want a full session history they can audit and replay, but they do not want to force the model to read all of it every turn.
Another trend is explicit infrastructure for long-running work. LangGraph emphasizes durable execution and resumability, while managed harnesses from model providers are starting to package checkpointing, permissions, and memory into the runtime itself.
That should help teams ship stateful AI systems faster, but it also raises the bar for governance. Once memory becomes the default infrastructure, sloppy write rules will stop being a minor bug and start being an operational problem.

Innovations in cognitive frameworks
Research is also pushing memory frameworks past plain retrieval. A January 2026 paper on Active Context Compression reported a 22.7% token reduction, from 14.9 million to 11.5 million tokens, on a small SWE-bench Lite sample while keeping the same accuracy.
Another 2026 paper on memory control argued for a bounded internal state that separates artifact recall from state commitment, which is a fancy way of saying the agent should not treat every retrieved fact as something worth remembering forever.
That is a useful direction. The next wave of memory architectures will likely look less like bigger chat logs and more like compact operating systems for reasoning: clear state objects, deliberate consolidation, and selective forgetting.
Final Takeaway: Memory Is No Longer a Feature
The biggest lesson I have learned from watching agent systems mature is simple: memory is not a cute personalization feature anymore. It is the control layer. Agent Memory and Context now decides whether an AI agent feels reliable, fast, personal, and safe, or whether it becomes a confused intern with unlimited sticky notes.
The best teams in 2026 handle the state with discipline. They store the full state outside the model. They compile only the right context into each turn. They separate short-term and long-term memory. They use caching and compaction carefully. They treat memory as useful, but never blindly trusted. That is the real maturity curve. Not “How much can the model remember?”
But:
What should the system remember, why should it remember it, when should it retrieve it, and who gets to control it?
Frequently Asked Questions (FAQs) About Agent Memory and Context
1. What Is The Difference Between Agent Memory and Context?
Agent memory is the information an AI agent can store and reuse later, such as user preferences, project rules, or past task patterns. Context is the selected information the model sees right now to answer or act. In simple terms, memory is the long-term storage, while context is the temporary working view sent to the model.
2. Why Is Agent Memory Important in 2026?
Agent memory is important in 2026 because AI agents are no longer just answering single questions. They now handle multi-step tasks, use tools, remember user preferences, and continue work across sessions. Without proper memory and state management, agents can become confused, expensive, slow, or even unsafe.
3. How do the best teams handle state?
Best teams treat state like a map; they track changes, prune old facts, and keep only what helps the agent act.
4. How do teams keep agent memory useful and safe?
They keep agent memory lean, like a tidy toolbox. They log state changes and prune old contexts. People review outputs, and they test for bias and errors.
5. What tools help manage agent memory and context?
Teams use memory stores, context windows, and simple data stores that save key facts. They add automation, monitoring, and clear rules so agents stay on task, and people can step in.