Worried that your AI helper could leak a file, call the wrong tool, or give an attacker a shortcut into your business? That fear is reasonable because AI Agent Security gets complicated the moment an agent can read data, use APIs, and take action for you.
What trips most teams up is simple: the model is only one piece of the risk. The real danger shows up where prompts, tools, memory, tokens, and automation meet.
In the Cloud Security Alliance’s March 24, 2026, survey, 68% of organizations said they could not clearly distinguish human from AI agent activity, and 74% said agents often received more access than necessary. That is why strong access control and visibility matter just as much as model quality.
I’m going to walk you through what can go wrong, what deserves your attention first, and the fixes that make the biggest difference.
Key Security Risks in AI Agent Security
AI Agent Security breaks down in predictable places. The highest-risk failures usually involve untrusted instructions, unsafe tool use, poisoned memory, borrowed privileges, and code execution paths that should never have been open.
| Risk | What it looks like | Why it matters | Best first move |
|---|---|---|---|
| Prompt injection | A hidden instruction in a webpage, email, PDF, or chat message changes agent behavior | The agent can leak data or take the wrong action | Treat all external content as untrusted input |
| Tool and API misuse | The agent calls the wrong connector, endpoint, or function | One bad call can expose records or modify systems | Allowlist tools and validate parameters |
| Memory and data poisoning | Bad records enter memory, retrieval, or training data | The agent makes flawed decisions later | Track provenance and review memory writes |
| Privilege escalation | An agent inherits broad user or service account rights | The blast radius becomes much larger | Give each agent its own limited identity |
| Remote code execution | Tool output or project files trigger command execution | An attacker can gain deep control fast | Sandbox execution and require approval gates |
Prompt Injection Attacks
Prompt injection is still the risk most teams underestimate. OpenAI describes it as an evolving security challenge, and the core problem is that third-party content can smuggle instructions into the same context window as trusted instructions.
That matters because an agent does not just answer questions. It may search, summarize, send messages, create tickets, or call tools, so one poisoned input can turn into a chain of bad actions.
A bad prompt can be an open door to secrets.
A real-world example made that clear on June 11, 2025, when NVD published CVE-2025-32711 for Microsoft 365 Copilot, describing it as an AI command injection issue that could disclose information over a network. If a production assistant can be steered this way, your internal agent can too.
- Separate trusted instructions from untrusted content such as emails, files, search results, and tool output.
- Require a confirmation step before any high-impact action like sending an email, spending money, or changing records.
- Scan both prompts and responses for injection patterns, not just the first user message.
- Log the exact input chain so you can see which source changed the agent’s behavior.
Tool and API Manipulation
Agents become much riskier the moment they can touch tools. A prompt does not need to steal data directly if it can persuade the agent to call an outbound email function, hit a raw HTTP endpoint, or use a connector with broad rights.
Microsoft’s February 2026 security guidance for agents is useful here: restrict email actions to approved domains or hardcoded recipients, avoid AI-controlled dynamic inputs for sensitive outbound actions, and prefer official connectors over raw HTTP requests. That advice is practical because it removes the easy exfiltration paths attackers look for first.
Tool misuse also hides inside convenience features. If your team lets the model decide email recipients, external endpoints, or execution logic for sensitive actions, you have turned a language model into a policy engine, and that is a bad trade.
- Keep a strict allowlist of tools the agent may call in production.
- Validate every parameter against schema, type, and policy rules before execution.
- Block nonstandard ports and require HTTPS for approved HTTP-based actions.
- Disable unused connectors, stale integrations, and test actions after launch.
Data and Memory Poisoning
Poisoning is dangerous because the failure often appears later. A bad document, a tampered knowledge base entry, or a manipulated memory write can quietly change how the agent behaves for days or weeks.
NIST’s Generative AI Profile recommends provenance tracking for training data and metadata, robust version control, and real-time auditing tools that help validate the lineage and authenticity of AI-generated data. In plain terms, you need to know where a memory item came from, who wrote it, and whether it should still be trusted.
Memory deserves extra caution because agents reuse it. A single poisoned summary can keep resurfacing in future decisions, especially in retrieval-heavy workflows.
| Poisoning point | Common failure | Safer practice |
|---|---|---|
| Training or fine-tuning data | Biased or malicious examples shape future output | Curate data sources and keep signed dataset versions |
| Retrieval index | Tampered documents influence answers and actions | Review source trust and reindex from approved repositories only |
| Long-term memory | Bad facts persist across sessions | Require policy checks before memory is written or reused |
Privilege Escalation and Authentication Spoofing
Many agent breaches are really identity problems. The agent gets too much access, borrows a human identity, or runs through a shared service account that nobody fully owns.
That is not a fringe issue. In the Cloud Security Alliance’s March 2026 survey, 52% of organizations said agents at least sometimes inherit access meant for humans or other systems, and 79% said agents create new access paths that are hard to monitor.
Authentication spoofing makes that worse. If a forged token, replayed session, or overly broad delegated credential gets accepted, the system may treat the attacker as a trusted user and the agent as a trusted operator at the same time.

Stop giving agents the keys to the kingdom, lock each door instead.
- Assign each agent a separate identity instead of letting it live inside a human account.
- Use short-lived tokens and rotate them automatically.
- Bind tokens to specific tasks, scopes, and environments.
- Require stronger checks when the agent changes context, device, location, or privilege level.
Remote Code Execution
Remote code execution is the nightmare scenario because it moves the problem from bad answers to system compromise. Once an agent can execute shell commands, install packages, or run project hooks, the line between assistant and attack surface disappears.
There is a recent example worth paying attention to. On February 25, 2026, Check Point disclosed patched Claude Code vulnerabilities, including CVE-2025-59536, showing that malicious project configurations could trigger remote code execution and API key theft when users opened untrusted repositories.
The lesson is clear: if your agent can execute code, read local files, or touch credentials, treat every repository, tool output, and config file as hostile until proven safe.
- Run code-capable agents inside hardened containers or sandboxes.
- Block internet egress by default and open only the destinations you approve.
- Require human approval for command execution outside a narrow safe list.
- Keep secrets out of environment variables when a workspace or repo can influence execution.
Common Vulnerabilities in AI Agent Systems
Even well-meaning teams create fragile agent systems. The problem is rarely one dramatic bug; it is the stack of small shortcuts that remove visibility, weaken access control, and let one bad decision spread.
NIST said on January 12, 2026, that AI agent systems face distinct risks when AI outputs are combined with software capabilities, including indirect prompt injection, insecure models exposed to data poisoning, and harmful actions that can happen even without adversarial input. That is a good reminder that ordinary software controls still matter, but they must now cover agent behavior too.
Expanded Attack Surface
Every new tool, plugin, connector, vector store, browser session, and memory layer expands the attack surface. If your agent can read from one place, write to another, and call a third service, the attacker only needs one weak link.
Microsoft’s 2026 guidance also highlights a quieter issue: orphaned agents. These are agents that keep running after the owner leaves or the account changes, and they often keep stale permissions, old connections, and outdated logic long after the team has forgotten them.
- Shadow agents created outside of IT review
- Shared service accounts with unclear owners
- Unused actions and stale connections left in production
- Raw HTTP actions that bypass safer, governed connectors
Autonomous Actions and Cascading Failures
An agent can take one wrong step and then amplify it. It may misread a document, call the wrong tool, write a bad memory, notify the wrong system, and then use that bad state to justify its next action.
This is where AI Agent Security becomes a workflow problem, not just a model problem. You need limits on what the agent may decide alone, what must be approved, and what must be reversible.
| Failure pattern | What happens next | Control that slows it down |
|---|---|---|
| Bad retrieval result | Agent trusts poisoned content | Source reputation checks and approval for high-impact actions |
| Wrong tool choice | Data is sent or changed in the wrong system | The tool allows and per-tool policy gates |
| Over-broad token | One mistake touches many systems | Task-scoped credentials and rapid revocation |
| Unsafe memory write | Future sessions repeat the mistake | Memory review, expiration, and provenance tags |
Lack of Transparency and Unpredictable Inference
Agents are hard to secure if you cannot explain what they saw, what they decided, and why they acted. A clean chat transcript is not enough when the real decision path includes retrieved files, tool responses, system prompts, memory, and policy checks.
This is why visibility is a first-class control. If you cannot reconstruct the chain of input, identity, decision, tool use, and output, incident response turns into guesswork.
The practical fix is boring and powerful at the same time: log prompts, retrieved sources, tool calls, memory writes, tokens, approvals, and final actions in one place. That single record gives your team a shot at fast containment.
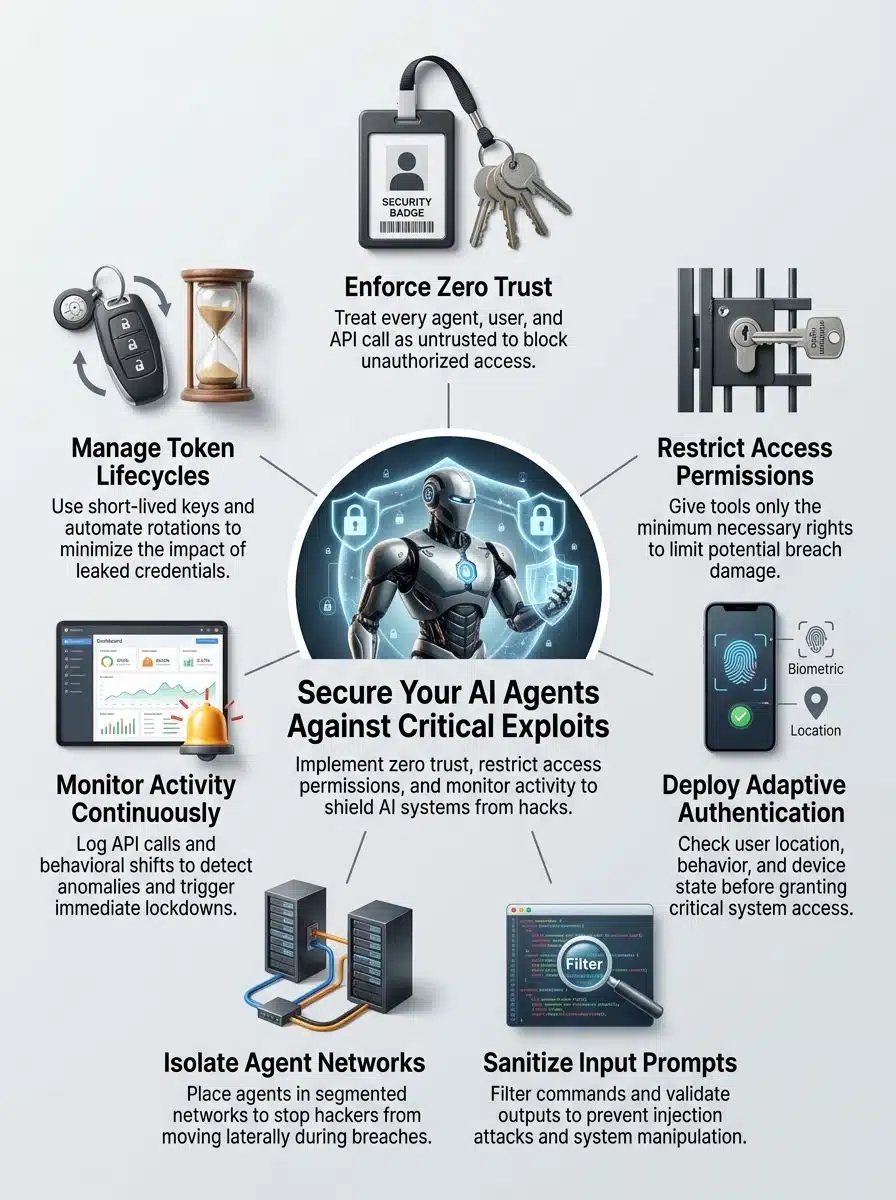
Preventative Measures for AI Agent Security
The best defenses are layered. You want to reduce what the agent can reach, narrow what it is allowed to do, and make every meaningful action visible.
- Assume every external input may be hostile.
- Assume every token will eventually be exposed.
- Assume every high-impact action needs either validation, approval, or both.
Zero Trust Architecture
NIST Special Publication 800-207 says zero trust means there is no implicit trust based on network location or asset ownership. That fits agents perfectly, because an internal agent can still be dangerous if it is over-permissioned or manipulated.
For agents, zero trust means each request should be evaluated by identity, context, device, and policy before access is granted. It also means you protect resources, not just the network edge.
A good starting pattern is to put agents behind a policy layer that checks who the agent is, what task it is performing, which tool it wants, and whether that action belongs in the current environment.
The Principle of Least Privilege
Least privilege is where AI Agent Security becomes practical. Give the agent access only to the minimum tools, data, and scopes it needs for one job, then expire that access quickly.
If an agent schedules meetings, it should not also be able to read payroll files. If it summarizes support tickets, it should not have write access to your production database.
- Create separate identities for separate agent roles.
- Scope tokens to one tool set or workflow, not to a whole platform.
- Review delegated access regularly, especially for connectors built during testing.
- Remove creator credentials from tools that still rely on them.
Context-Aware Authentication
Static authentication is too weak for autonomous systems. Agents change context fast, and the trust decision should change with them.
Use stronger checks when risk rises, such as when an agent moves to a new environment, requests a privileged tool, or starts acting outside its normal schedule. This is where short-lived credentials, conditional policies, and step-up approval help.
NCCoE is now exploring standards-based approaches for software and AI agent identity and authorization, which tells you the market is moving toward formal agent identity, not improvised service accounts.
Prompt Hardening and Validation
Prompt hardening is less about clever wording and more about boundaries. You want clear instructions, strict variable handling, schema checks, and guardrails that stop the model from improvising in places where improvisation is dangerous.
Google Cloud’s Model Armor is one example of how this is becoming an operational layer. It screens prompts, responses, and agent interactions for prompt injection, sensitive data leaks, malicious URLs, and harmful content, which is useful when you need runtime checks instead of one-time prompt edits.
- Sanitize inbound text and mark external content as untrusted before it reaches the model.
- Use templates for sensitive workflows instead of free-form tool instructions.
- Validate model output against a schema before any tool call runs.
- Require explicit approval for external messages, purchases, file deletion, and administrative changes.
- Test prompts with adversarial cases on a schedule, not only before launch.
Microsegmenting and Network Isolation
Flat networks make agent mistakes much more expensive. If the agent can laterally move from one environment to another, a single bad token or tool abuse event can spread fast.
Microsegmentation shrinks the blast radius. Put agents, vector stores, tool gateways, and sensitive back-end systems into tightly separated zones, then allow only the traffic you can justify.

| Isolation layer | What it protects against | What to enforce |
|---|---|---|
| Separate runtime network | Lateral movement | Only approved east-west traffic |
| Tool gateway | Unsafe outbound calls | Allowlisted services and parameter checks |
| Container sandbox | Unexpected code execution | Limited file access and blocked privileged commands |
| Secrets vault | Credential leakage | No hard-coded secrets and fast revocation |
Advanced Security Strategies
Once the basics are in place, advanced defenses help you catch what slips through. This is where testing, telemetry, and behavior controls turn a decent setup into a resilient one.
Adversarial Training for Threat Defense
Adversarial training means you intentionally expose the system to hostile prompts, malformed input, and poisoned context so you can see where it fails. It is one of the best ways to find weaknesses before attackers do.
NIST’s Generative AI Profile recommends red-teaming and ongoing evaluation of risk controls, especially for privacy, data exposure, and output integrity. That matters because agents fail in combinations, not in neat single-bug categories.
Good adversarial testing should include prompt injection, tool misuse, credential abuse, poisoned retrieval content, and malicious file handling. If your tests cover only chat behavior, you are missing the dangerous part.
Real-Time Monitoring and Threat Detection
Monitoring is what turns AI Agent Security from hope into control. You need to know when an agent accessed a record, called a tool, changed a file, used a token, or deviated from its normal pattern.
NIST also recommends real-time auditing tools to track lineage and authenticity. In practice, that means your logs should not stop at the model response; they should capture the full action trail.
- Log prompts, retrieved context, tool calls, approvals, and outputs together.
- Correlate agent actions with identity, token scope, and human owner.
- Alert on unusual volume, off-hours activity, new destinations, and privilege changes.
- Pipe events into your SIEM so incident response does not depend on manual reconstruction.
Behavioral Analytics and Anomaly Detection
Behavioral analytics helps because agents often fail by acting slightly differently before they fail catastrophically. They may query more data than usual, attempt new tools, or repeat a pattern that no human reviewer would allow.
The useful move here is to establish a baseline per agent role. Your research assistant, support agent, and coding agent should not all be judged by the same behavior profile.
Anomaly detection works best when it has context. A spike in file access may be fine during a planned migration, but it is suspicious when it appears alongside new tool calls and a recently issued token.
Multi-Agent Collaboration Security
Multiple agents can share context, tools, memory, and mistakes. That means one compromised agent can become a stepping stone into another workflow.
OWASP’s current agentic security guidance puts tool misuse, identity abuse, memory poisoning, and cascading failures near the center of the problem. Multi-agent systems combine all four, so the controls must be tighter, not looser.
- Do not let agents freely trust data from other agents.
- Require signed or policy-checked handoffs for shared memory and inter-agent messages.
- Limit cross-agent token reuse and rotate credentials when workflows change.
- Log which agent acted, on whose behalf, with which tool, and with which result.
Implementation Best Practices
The fastest way to improve AI Agent Security is to treat it like a shipping discipline. Build security into the workflow, keep permissions narrow, and rehearse failure before production traffic forces the lesson on you.
Secure by Design, DevSecOps Integration
CISA has stressed that AI is software and should be secure by design, and that is the right mindset. Security cannot be a cleanup task after the agent already has access to data and tools.
- Threat model every new agent before it touches production systems.
- Add prompt, connector, secret, and dependency checks to CI pipelines.
- Block hard-coded credentials and scan for leaked keys on every commit.
- Review tool permissions as carefully as application permissions.
- Keep a named owner for every agent in production.
If an agent has no clear owner, no clear scope, and no review path, it is a future incident waiting to happen.
Token Lifecycle Management
Tokens are often the quiet weak spot. A powerful agent with a long-lived token can stay dangerous even after you fix the original bug.
The safer pattern is short-time-to-live credentials, automatic rotation, rapid revocation, and tight scoping. That way, even if a token leaks through logs, memory, or a malicious tool path, the attacker’s window stays small.
| Token practice | Why it helps |
|---|---|
| Short-lived tokens | Cut the useful life of stolen credentials |
| Task-level scopes | Reduce the blast radius if the agent is compromised |
| Automatic rotation | Remove reliance on manual cleanup |
| Immediate revocation hooks | Speed containment during incident response |
| Vault-based secret storage | Keep tokens out of code, logs, and prompts |
Regular Security Testing and Adversarial Validation
Security testing for agents needs more than a standard penetration test. You also need prompt injection tests, retrieval poisoning tests, connector abuse tests, and workflow-level simulations that show how one bad decision spreads.
A useful schedule is quarterly deep testing, plus lighter automated checks in every release cycle. If your agent changes tools or permissions, test again right away.
- Run penetration tests against tool gateways, auth flows, and agent runtimes.
- Fuzz API inputs and output-handling paths to catch unsafe execution logic.
- Use red-team scenarios that include data exfiltration, privilege escalation, and poisoned files.
- Measure mean time to detect, mean time to revoke, and mean time to contain.
The goal is not perfect safety. The goal is to find the weak path before an attacker does, then make recovery fast and boring.
Wrapping Up
AI Agent Security is not an extra feature; it is the control system that keeps a helpful agent from becoming a liability. Lock down access control, validate every high-impact action, and keep full visibility into what each agent can reach and what it actually does.
Start with least privilege, prompt hardening, token discipline, and network isolation. Those four moves will lower risk quickly and give your team a much better shot at prevention, detection, and incident response.
Frequently Asked Questions About AI Agent Security
1. What can go wrong with AI agents?
AI agents can be tricked by bad inputs, leak private data, or be used to steal the model, and they can take harmful actions. That can hurt users and firms, like a guard dog chasing the wrong scent.
2. How do attackers trick AI agents?
Attackers send crafted prompts, use input tricks, run email scams, or mount database attacks to gain access or force wrong outputs.
3. How can teams prevent these problems in AI agent security?
Use strong authentication, strict access control, and data encryption, keep logs, and monitor behavior. Run tests, use canaries to spot odd actions, and add human review for risky tasks.
4. Who should own AI agent security, and what tools help?
Security teams, software developers, product owners, and data teams must share responsibility. Use threat models, testing suites, monitoring tools, and regular audits. Think of audits like oil changes; they keep systems running.