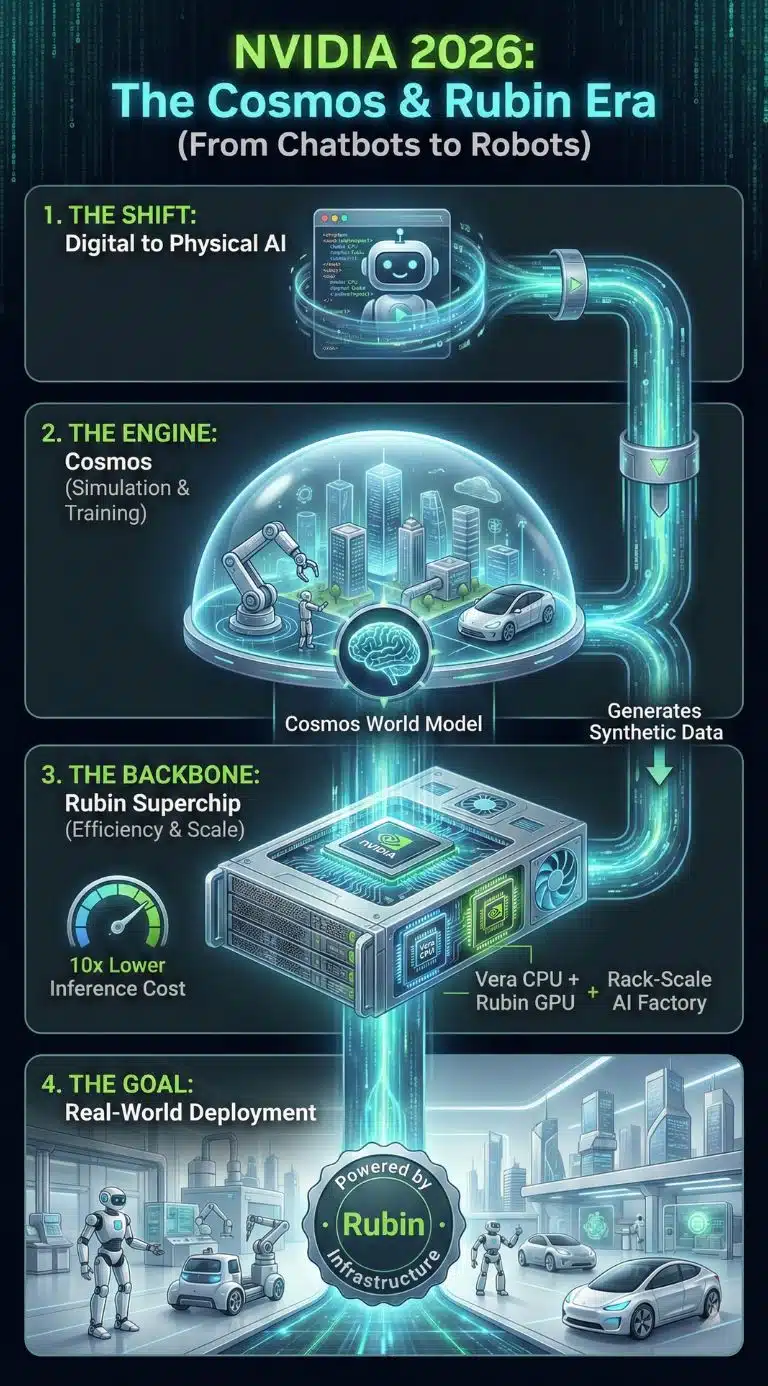
NVIDIA Cosmos is arriving as AI moves from chatbots to the physical world, and NVIDIA is pairing that shift with its Vera Rubin Superchip roadmap. Together, they aim to make robots and “AI factories” cheaper to train, safer to scale, and easier to run in 2026.
How We Got Here: From CUDA’s Edge To Full-Stack AI Systems
For years, NVIDIA’s advantage was straightforward: great GPUs, plus CUDA, plus an ecosystem that made switching costs real. Deep learning turned that advantage into a platform, and the generative AI boom turned the platform into a global dependency.
But the generative era also changed what “winning” means. The market is moving from buying chips to buying outcomes. Enterprises want predictable cost per token, stable uptime, secure multi-tenant deployment, and faster iteration cycles for new applications. At the same time, the frontier of AI is shifting toward multimodal and agentic systems that stress memory bandwidth, networking, orchestration overhead, and power budgets as much as raw compute.
This is the environment where Cosmos and Rubin make sense as a single thesis.
-
Cosmos targets the physical AI bottleneck: data scarcity, edge cases, and safe training for robots and autonomy.
-
Rubin targets the economic bottleneck: inference cost, rack-scale utilization, and systems designed to run reliably as “AI factories” rather than as clusters of parts.
The deeper story is strategic. NVIDIA is trying to define the next default stack for AI, where simulation and synthetic data feed physical-world deployment, and rack-scale designs decide profitability.
Why Cosmos Matters: World Models As The Next Data Flywheel
Cosmos is NVIDIA’s attempt to industrialize “world models,” systems that can simulate plausible physical environments so other models can learn, plan, and act. The point is not just generating pretty video. The point is accelerating the feedback loop that physical AI needs: test, fail, learn, repeat, without breaking robots or waiting months for real-world data collection.
NVIDIA has framed Cosmos as a “world foundation model” platform for physical AI, designed to be fine-tuned into specialized models for robotics and autonomous systems. The attention-grabbing claim is scale: pretraining on 9,000 trillion tokens and drawing from 20 million hours of data across domains relevant to autonomy and robotics.
That scale is meaningful because physical AI has a different data problem than text AI. Language models can ingest the internet. Robots cannot safely ingest the internet of real-world mistakes. They need controlled exposure to rare hazards, long-tail edge cases, and multi-sensory signals. Simulation becomes the only scalable substitute, and world models become the engine that makes simulation more realistic and more varied.
Cosmos In Practice: Predict, Transfer, Reason
NVIDIA positions Cosmos as a set of capabilities that map to real development workflows:
-
Predict: generate plausible future states from multimodal inputs.
-
Transfer: convert structured simulation signals into photorealistic outputs for training data.
-
Reason: interpret video and outcomes in natural language to help evaluate behavior, label data, and debug systems.
The practical bet is that robotics teams can move faster by using world models to create more training scenarios than real-world collection could ever provide. If that bet is right, “data advantage” in physical AI becomes less about having fleets on the road and more about having the best synthetic pipeline, the best scenario coverage, and the best evaluation harness.
Cosmos Workflow Snapshot
| Cosmos Capability | What It Takes In | What It Produces | Why It Helps Physical AI Teams |
|---|---|---|---|
| Predict | Text, images, video | Plausible world evolution and scenarios | Scales safe experimentation and policy testing |
| Transfer | Depth, segmentation, lidar-like signals, trajectories | Controllable photoreal training data | Makes synthetic data closer to reality, faster |
| Reason | Video plus context | Explanations, outcome reasoning, summaries | Speeds evaluation, labeling, and debugging |
Rubin Matters For A Different Reason: Inference Economics Are Becoming The Real Battlefield
Training is glamorous, but inference pays the bills. As AI products mature, the operational cost of serving models becomes a dominant constraint. This is especially true as systems move toward long-context reasoning, multimodal inputs, and agentic loops that require multiple inference passes per user request.
NVIDIA’s Rubin platform is meant to lower cost per token while improving rack-scale efficiency. The company’s headline messaging emphasizes tight integration across CPU, GPU, networking, and security, packaged as a unified “AI supercomputer” concept rather than a shopping list of parts.
Rubin is also framed as a rack-scale platform, with designs such as NVL72 and other configurations meant to behave like a production line: feed it data, keep it saturated, and ship tokens.
NVIDIA’s public claims include:
-
Up to 10x lower inference token cost versus the prior generation baseline it references.
-
4x fewer GPUs to train MoE models compared with the previous platform it benchmarks against.
Even allowing for marketing optimism, the direction aligns with industry pressure. AI is running into a wall where the marginal benefit of bigger models must be justified by a cheaper, more reliable serving stack.
What “Vera Rubin Superchip” Implies
“Superchip” in NVIDIA’s roadmap language typically signals tight CPU-GPU coupling with high-bandwidth links designed to reduce orchestration overhead and data movement penalties. Reporting around the Vera Rubin Superchip concept has described a Vera CPU design with 88 custom Arm cores and 176 threads, coupled via 1.8 TB/s CPU-GPU connectivity.
Why that matters:
-
Agentic AI adds coordination overhead. More system time is spent planning, routing, and managing memory and tools. Faster CPU-GPU cooperation matters.
-
Rack-scale design beats component design. In production, the winner is often the system that is easiest to keep running at high utilization with predictable performance.
Rubin Platform Snapshot
| Layer | What NVIDIA Is Emphasizing | What It Optimizes In Practice |
|---|---|---|
| CPU + GPU coupling | Vera CPU paired tightly with Rubin GPU | Lower overhead and faster pipelines for agentic workloads |
| Rack-scale NVLink switching | NVLink scale-up fabrics as a core product | Higher utilization and faster multi-GPU collaboration |
| Networking and DPUs | SuperNICs and DPUs for data movement and security | Better throughput under real cluster conditions |
| Confidential computing | Security features built into rack-scale designs | Enterprise and sovereign deployment requirements |
Cosmos and Rubin reinforce each other. Cosmos pushes more developers and enterprises toward simulation-heavy workflows. That increases demand for compute, and it increases demand for efficient inference and training pipelines. Rubin is meant to keep that demand economically survivable.
Two structural shifts make this pairing powerful:
Physical AI Will Train In Simulation First
Robots cannot learn at scale through real-world mistakes. Simulation, synthetic data, and controllable edge-case generation become the default route. Cosmos is designed to reduce the time and cost of building those training corpora.
Inference Cost Will Decide Who Can Scale
The next wave of AI adoption will be gated by operational economics. Cheaper tokens and higher utilization expand what is commercially viable, especially for agents, multimodal assistants, and industrial deployments.
The Real Bottlenecks: Power, Grid Capacity, And Memory Supply
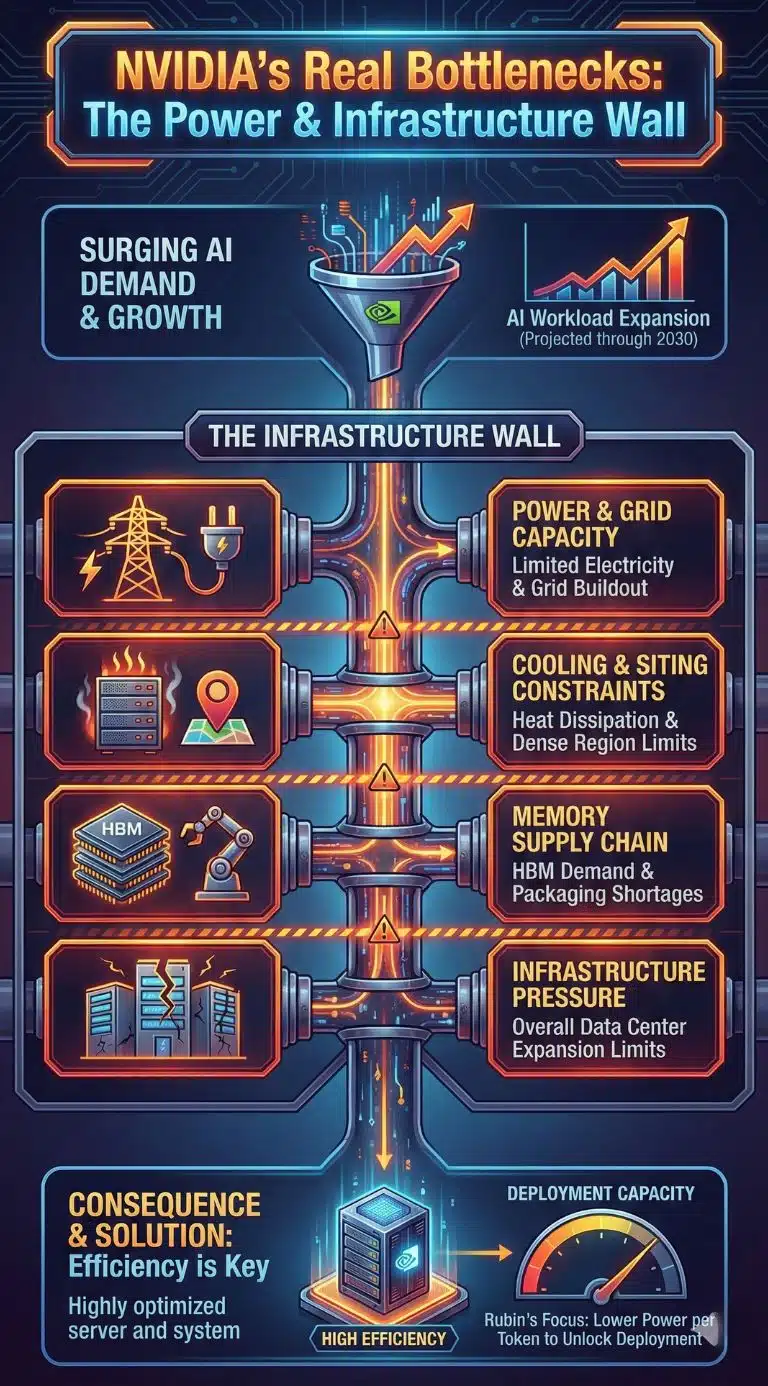
If the last decade of AI was constrained by compute availability, the next decade may be constrained by infrastructure.
Energy agencies and market analysts have increasingly highlighted the power implications of AI-optimized data centers, projecting significant growth in electricity demand tied to data center expansion and AI workloads through 2030. The takeaway for readers is not a single number. It is the pattern: power and cooling are becoming first-order constraints that shape where AI can be deployed and how quickly.
This helps explain why NVIDIA’s messaging leans hard on cost per token and efficiency improvements. When electricity, grid buildout, and permitting become gating factors, efficiency gains translate directly into real deployment capacity.
Energy And Infrastructure Pressure Snapshot
| Pressure Point | What The Trend Looks Like | Why It Matters For Rubin-Class Systems |
|---|---|---|
| Electricity demand from data centers | Rising sharply through 2030 | Limits where “AI factories” can expand |
| AI-optimized workloads | Growing faster than general compute | Efficiency becomes a competitive advantage |
| Cooling and siting | More constrained in dense regions | Pushes investment toward new geographies |
| Memory supply | HBM demand and packaging constraints | Limits system shipment pace and pricing power |
Key Statistics That Signal The Direction
-
Cosmos scale claims: 9,000 trillion tokens and 20 million hours of data in pretraining and curation narratives.
-
Accelerated curation framing: 20 million hours processed in 14 days on accelerated pipelines (as presented by NVIDIA in its platform narrative).
-
Rubin economics framing: up to 10x lower inference token cost and 4x fewer GPUs for MoE training in NVIDIA’s public positioning.
-
Rubin Superchip framing: 88 Arm cores, 176 threads, and 1.8 TB/s CPU-GPU connectivity described in reporting around the roadmap.
These figures matter less as isolated brag points and more as signals of where the industry is headed: system-scale design, synthetic data pipelines, and economics-first deployment.
A Comparative View: Who Benefits, Who Gets Squeezed
| Likely Winners | Why | Likely Pressured Players | Why |
|---|---|---|---|
| Hyperscalers and well-funded neoclouds | Can buy and deploy rack-scale stacks quickly | Smaller AI startups | Higher marginal cost per experiment and per token |
| Industrial robotics and automation firms | Faster training via synthetic pipelines | Point-solution robotics vendors | Harder to compete with platform-level tooling |
| Memory and packaging supply chain leaders | HBM and packaging become strategic | Regions with grid constraints | Slower deployment and higher operating costs |
| Security-first enterprises and governments | Confidential computing becomes a procurement requirement | Vendors betting only on “cheap inference” | Baseline costs may fall, narrowing differentiation |
Competition And Counterarguments: Hyperscalers Want Independence
A neutral analysis has to acknowledge the central tension. NVIDIA wants to be the default fabric of AI compute. Hyperscalers want flexibility and negotiating power, and many are investing heavily in custom accelerators.
NVIDIA’s defense is integration. It is pushing a view that the system matters more than the part, and that networking, interconnect, orchestration, and developer tooling form the durable moat. Even if some workloads shift to alternative accelerators, NVIDIA can still try to own the rack-scale standards and the performance-per-watt story through tightly engineered stacks.
A second counterargument is adoption pace. Physical AI is hard. World models can accelerate training, but they do not eliminate the messy realities of deployment: safety certification, liability, maintenance, and real-world unpredictability. Cosmos can shorten iteration cycles, but it cannot fully replace validation in real environments.
What Comes Next: Milestones To Watch In 2026
The next year will clarify whether Cosmos and Rubin represent a durable platform shift or an ambitious roadmap.
Milestones To Watch
| Window | Milestone | Why It Matters |
|---|---|---|
| 2026, early to mid-year | Evidence of broad Cosmos adoption in robotics and autonomy workflows | Shows whether world models become standard tooling |
| 2026, mid to late-year | Rubin-based systems reaching customers at scale | Reality check on availability, integration, and performance |
| 2026 onward | Measurable inference cost declines for real products | Proves that token economics improve in practice |
| 2027 | Next-step roadmap execution | Tests whether NVIDIA’s cadence remains credible |
Three Predictions, Clearly Labeled
-
Likely: Enterprises will increasingly buy integrated “AI factory” stacks rather than piecemeal hardware, because utilization, reliability, and security matter more than peak benchmarks.
-
Plausible: Synthetic data pipelines will become the default route for physical AI development, and teams with the best scenario coverage will outperform teams with the most real-world data.
-
Uncertain: Power and grid constraints will slow AI deployment more than chip supply in certain regions, pushing AI infrastructure investment into new geographies and policy frameworks.
Final Thoughts: Why This Matters Now
NVIDIA Cosmos and the Vera Rubin Superchip storyline is really about one question: what becomes the default platform for the next phase of AI.
The first wave of generative AI standardized around cloud GPUs and large language models. The next wave looks like simulation-driven physical AI paired with rack-scale compute designed for low-cost inference and high utilization. If NVIDIA succeeds, it will not just sell faster silicon. It will shape how AI is produced, trained, secured, and deployed at industrial scale.