

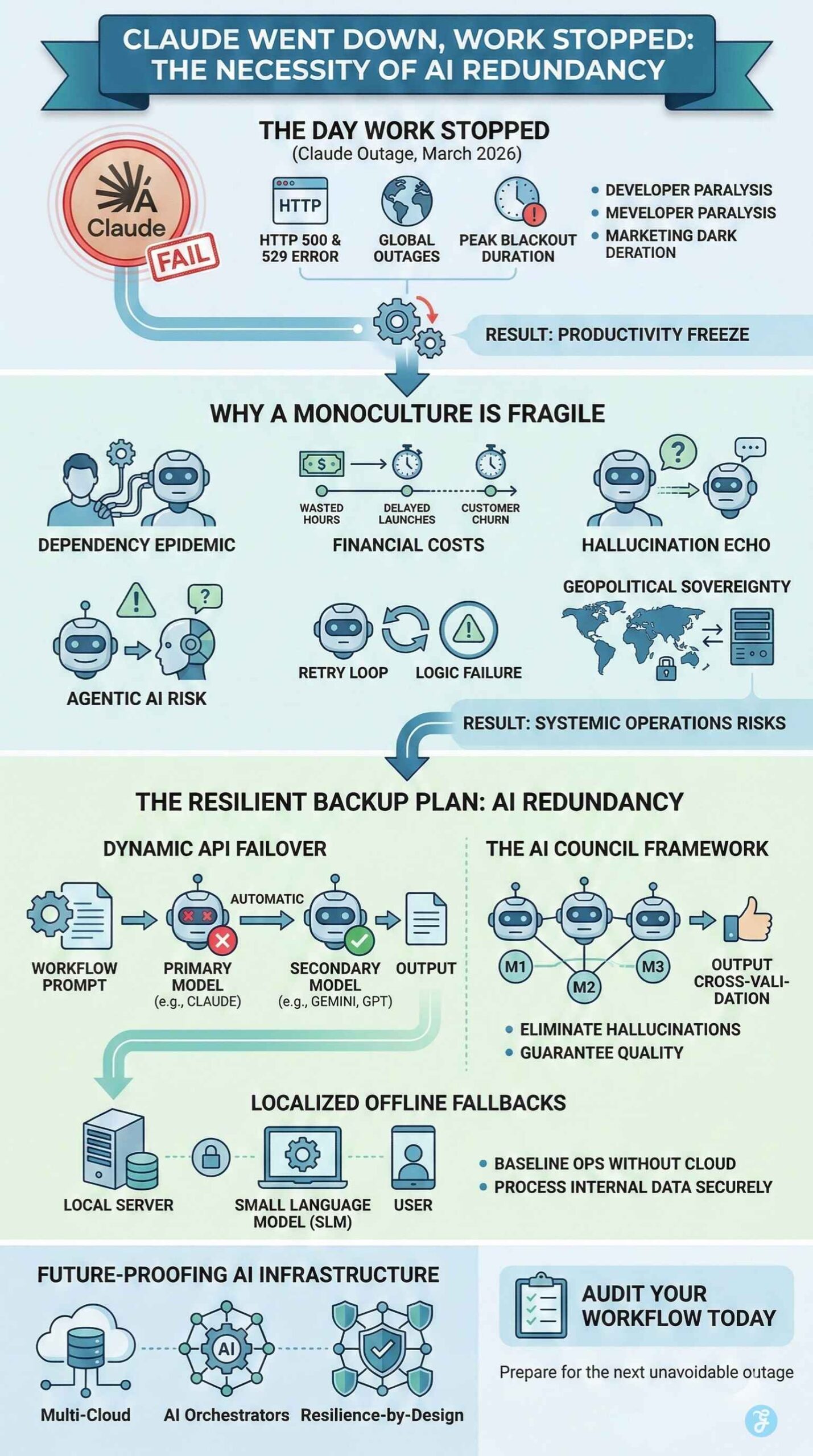
AI Redundancy is no longer a luxury for enterprise workflows. It is the fundamental baseline for operational survival. On March 2 and March 3 of 2026, the global technology sector experienced a massive reality check. Anthropic’s Claude suffered rolling global outages. Developers stared at the red HTTP 500 and 529 error screens. Marketing algorithms operating in the dark failed to execute their daily batch processes. The collective realization across the tech world was stark. Automated workflows had entirely frozen.
Artificial intelligence has quietly transitioned from a novelty chatbot into critical global infrastructure. We now treat these systems like electricity or running water. When the power goes out, work stops entirely because humans have lost the muscle memory or the sheer bandwidth to execute complex tasks manually.
As our reliance on these systems deepens into total dependency, building operations around a single provider becomes an unacceptable operational risk. A multi-model backup plan is now a strict business imperative.
Anatomy of an Outage: The Day the Prompts Stood Still
To understand why a backup plan is strictly necessary, we must deeply examine the technical failure that brought operations to a halt. The disruption began at 11:49 UTC on March 2. Users trying to access the web interface, the mobile applications, and the developer console encountered persistent login failures and connection hangs.
The root cause of this downtime was ironically a massive surge in popularity. This was the ultimate success tax on Anthropic. Following a highly publicized standoff with the US Pentagon over the use of artificial intelligence in mass surveillance and autonomous weapons, Anthropic refused federal military contracts. This ethical stance triggered a massive industry shift. Hundreds of thousands of users migrated away from competing platforms and flooded into the Claude ecosystem.
This viral influx of users completely overwhelmed the authentication systems. The control plane buckled under the weight of record-breaking traffic. Even though the core inference models might have been perfectly healthy, the login and session control paths failed.
The ripple effect was devastating across the board. It was not just individual users losing access. Enterprise customers relying on Claude for time-sensitive automated workflows experienced massive operational delays. Complex microservice topologies dictate that a localized degradation in an authentication server easily cascades into a multi-component incident.
Key Statistics from the March 2026 Outage:
| Metric | Recorded Impact |
| Free User Growth | 60 percent increase since January 2026 |
| Paid Subscriber Surge | 200 percent increase in the same timeframe |
| Platform Migration | 700,000 users migrated from competitors |
| Peak Blackout Duration | 3 hours of total system unresponsiveness |
The AI Dependency Epidemic
The outage exposed a deep psychological and operational shift in the modern workplace. We are currently witnessing an unprecedented dependency epidemic. Over the last two years, workers have integrated these models seamlessly into their daily muscle memory.
Cognitive offloading is the phenomenon where humans outsource core competencies to an external system. Developers now rely on these tools for writing boilerplate code and debugging complex syntax. Content managers depend on them for structuring daily publications and optimizing Answer Engine Optimization strategies. Quality assurance teams automate their testing scripts entirely through natural language commands.
When the system went down, the resulting paralysis was immediate and shocking. Social media platforms are flooded with reports of developers having to code manually for the first time in months. The underlying reality is quite serious. When a critical tool goes offline, teams do not simply revert to doing the work manually. They realize they have temporarily lost the stamina, the syntactical recall, and the capability to execute tasks at their normal velocity without their digital assistant.
Companies have optimized their pipelines for maximum speed and minimum cost using these tools. In doing so, they entirely forgot to account for the single point of failure this creates within their daily operations.
The Financial Cost of Artificial Paralysis
The psychological impact of the outage is only half the story. The immediate financial fallout reveals the true danger of lacking a failover strategy. When productivity across the technology sector drops drastically for even a few hours, the economic bleed is measurable and severe.
Enterprise teams do not just lose time. They lose the massive operational leverage that artificial intelligence provides. A senior developer utilizing a coding assistant operates at a significantly higher velocity than one writing manual syntax. When that assistant goes offline, the company is still paying top-tier salaries for a suddenly crippled workflow.
Furthermore, automated customer support systems that default to human agents during an API timeout create instantaneous bottlenecks. Support queues overflow rapidly. Resolution times spike to unacceptable levels. Customer satisfaction metrics plummet within minutes.
We can categorize the financial impact into three distinct risk zones.
Estimated Cost of Infrastructure Downtime:
| Disruption Zone | Direct Business Impact | Revenue Consequence |
| Engineering & Development | Code generation halts, and QA scripts fail | Wasted engineering hours and delayed product launches |
| Marketing & Advertising | Real-time ad bidding and content generation freeze | Lost impression share and frozen campaign scaling |
| Customer Success | Autonomous support agents crash | Increased ticket volume and potential churn |
If a company calculates its daily engineering burn rate, an unmitigated three-hour outage represents tens of thousands of dollars in evaporated productivity.
The Danger of the AI Monoculture
Relying entirely on one provider is the equivalent of flying a single-engine commercial plane with no contingency plan. This single-vendor vulnerability creates a highly fragile ecosystem.
Server downtime is only the most visible symptom of a monoculture workflow. Businesses face numerous silent failures when locked into one ecosystem. Unannounced model drift can occur. This is a situation where a system suddenly becomes lazy or refuses complex prompts following an unannounced backend update. Providers also implement aggressive rate limiting during peak hours. This throttles enterprise applications without warning and degrades the user experience.
Furthermore, relying on a single model amplifies the hallucination risk. If an application uses only one system to generate data, there is no secondary system to cross-reference the output. A monoculture workflow has no built-in mechanism to catch a fabricated fact or a flawed piece of code before it reaches production.
Operational Risks of Single-Vendor Dependency
| Risk Category | Description | Business Impact |
| Authentication Overload | User surge crashes login servers | Complete lockout from web apps and APIs |
| Model Drift | Unannounced updates degrade reasoning | Automated workflows fail silently |
| Rate Limiting | Provider throttles API calls during peak load | Applications timeout and drop user requests |
| Hallucination Echo | A single model fabricates information | Flawed data enters production environments |
Agentic AI and the Infinite Loop Risk
The risk multiplies exponentially when we look at the rapid rise of agentic systems. Unlike human-prompted chatbots, autonomous agents operate entirely in the background. They string together complex tasks, access proprietary databases, and execute actions without direct human supervision.
When an agentic workflow is built on a single provider ecosystem, an API timeout does not just stop a process. It can cause catastrophic logic failures. If an autonomous agent encounters an unexpected System Overloaded error, poorly configured error handling can send the agent into an infinite retry loop. This burns compute resources and API credits incredibly rapidly.
A monoculture agentic system is inherently brittle. True autonomous systems require a multi-model architecture to maintain their independence. If the primary reasoning engine fails, the agent must be able to seamlessly call upon a secondary model to diagnose the error and continue the workflow.
The Geopolitical Lens of AI Sovereignty
The March 2026 outages highlighted a vulnerability that extends far beyond corporate balance sheets. It brought the concept of data sovereignty and geopolitical risk to the absolute forefront of the technology debate.
The underlying catalyst for the user surge was a direct response to military contracting and mass surveillance debates. This proves that frontier models are not neutral utilities. They are deeply entangled in global power dynamics and national security frameworks.
When global enterprises or regional publications rely entirely on a single foreign-based provider, they subject their critical infrastructure to external regulatory shifts, geopolitical embargoes, and corporate policy changes. This is especially critical for regions dealing with sensitive political analysis or localized infrastructure projects. Relying on a centralized foreign server to process sensitive regional data presents a massive security vulnerability.
Building a robust redundancy strategy is a fundamental requirement for true data sovereignty.
Core Sovereignty Strategies:
- Deploying open weight models on regional servers to guarantee continuous access.
- Diversifying API reliance across providers based in different geopolitical jurisdictions.
- Ensuring critical government or financial data is never locked into a single proprietary cloud ecosystem.
Nations and international corporations cannot afford to have their digital economies frozen because a single company decides to alter its terms of service or experiences a server cascade. Resilience requires strict geographic and corporate diversification.
The Solution: Building an AI Redundancy Architecture

The only cure for dependency is resilience. Modern businesses must build dynamic API failovers to ensure continuous operation. This model-agnostic architecture separates the application layer from the specific provider.
The primary strategy is the failover mechanism. Businesses construct routing gateways that constantly monitor the health of the primary model. If the primary system returns an error, the router automatically and instantly switches the prompt to a secondary model. The end user never notices the disruption. The workflow continues without interruption.
A more advanced proactive strategy involves the council framework. Instead of querying a single system, mission-critical workflows query multiple models simultaneously. If one system fails, the others carry the load. If they all return an answer, the systems cross-validate each other to eliminate hallucinations and automatically select the highest quality response.
Modular integration is essential for this approach. By using API gateways, engineering teams can swap out models seamlessly without rewriting their core application logic. This preserves entity authority and ensures continuous Answer Engine Optimization without missing a single beat.
Localized Fallbacks: When the Cloud Goes Dark
Cloud redundancy is only step one. Step two involves preparing for broader internet or data center disruptions. There is a rapidly growing necessity for localized offline tools.
Small Language Models running on native hardware provide the ultimate safety net. While an offline model running on a company server or a user’s local machine might lack the vast reasoning capabilities of a frontier model, it ensures baseline operations survive. A local model can handle basic retrieval tasks, draft standard communications, and process internal data without relying on an external internet connection or a third-party authentication server.
This approach guarantees that even in the event of a total cloud blackout, content production, batch processing, and basic administrative tasks can continue securely and privately.
The Future of AI Infrastructure: Resilience by Design
The recent outages will permanently change enterprise software contracts and architectural philosophies. Customers are no longer asking which model is the absolute smartest. The primary question is now intensely focused on the resilience of the routing architecture.
This shift is driving the massive rise of agnostic platforms and orchestrators. Enterprise services now treat large language models as interchangeable compute engines. Blind loyalty to a specific brand is being rapidly replaced by a strict demand for guaranteed uptime.
Service Level Agreements are evolving at an unprecedented pace. Providers will soon be required to guarantee multi-region and multi-cloud availability. If a data center in one region experiences a disruption, the workload must automatically shift to a secure facility in another region without any human intervention.
Final Thoughts: Designing for the Inevitable
AI dependency is an inevitable byproduct of rapid technological progress. Systemic fragility is a choice. The days of treating these systems as infallible magic boxes are completely over. They are complex and vulnerable software services subject to the same traffic spikes, hardware failures, and political pressures as any other digital infrastructure.
The widespread paralysis caused by the recent outage proves that we have crossed a point of no return. We can no longer do our jobs without these tools. Therefore, we must engineer our systems to ensure these tools are always available.

































