

A critical failure within Amazon’s most important data center region triggered a 15-hour global internet blackout on Monday, October 20, 2025, demonstrating the profound fragility of the modern digital economy. The widespread Amazon’s AWS outage, which knocked services like Snapchat, Fortnite, Signal, and major banking applications offline, was not a hack, but a self-inflicted wound: a Domain Name System (DNS) error that caused core services to suffer “temporary internet amnesia.”
The October 20th AWS Meltdown
- What Happened: A massive service disruption at Amazon Web Services (AWS), originating in its US-EAST-1 (Northern Virginia) region.
- Date & Duration: The event began at approximately 11:49 PM PDT on October 19 (07:49 GMT, Oct 20) and lasted roughly 15 hours. AWS declared “normal operations” had returned by 3:01 PM PDT on October 20.
- The Root Cause: AWS identified a “DNS resolution issue” for the API endpoint of its core DynamoDB database service.
- The Domino Effect: The initial DNS failure cascaded, causing “increased error rates and latencies” in at least 37 other services, including EC2 (compute) and Network Load Balancers.
- Global Impact: Millions of users were affected. Outage tracker Downdetector logged over 8.1 million user reports for various downed services.
- Affected Services: A partial list includes Snapchat, Fortnite, Roblox, Signal, Zoom, Canva, Duolingo, Coinbase, Ring doorbells, Alexa, and Amazon’s own retail site, plus UK banking institutions like Lloyds and Halifax.
The Anatomy of a Digital Blackout: What Failed?
For millions, the internet simply broke. Workplaces using Slack, gamers on Fortnite, and households with Ring doorbells were simultaneously disconnected. The user’s question—why did so many different apps fail at once?—points to the highly concentrated nature of the modern cloud.
These apps were not all hosted on one giant server. Instead, they are built from dozens of micro-services. They use one AWS service for computing (EC2), another for storage (S3), and, critically, another for a fast, reliable database (DynamoDB).
The failure on Monday was a catastrophic breakdown in the system that connects these services.
The Initial Spark: A DNS Failure in US-EAST-1
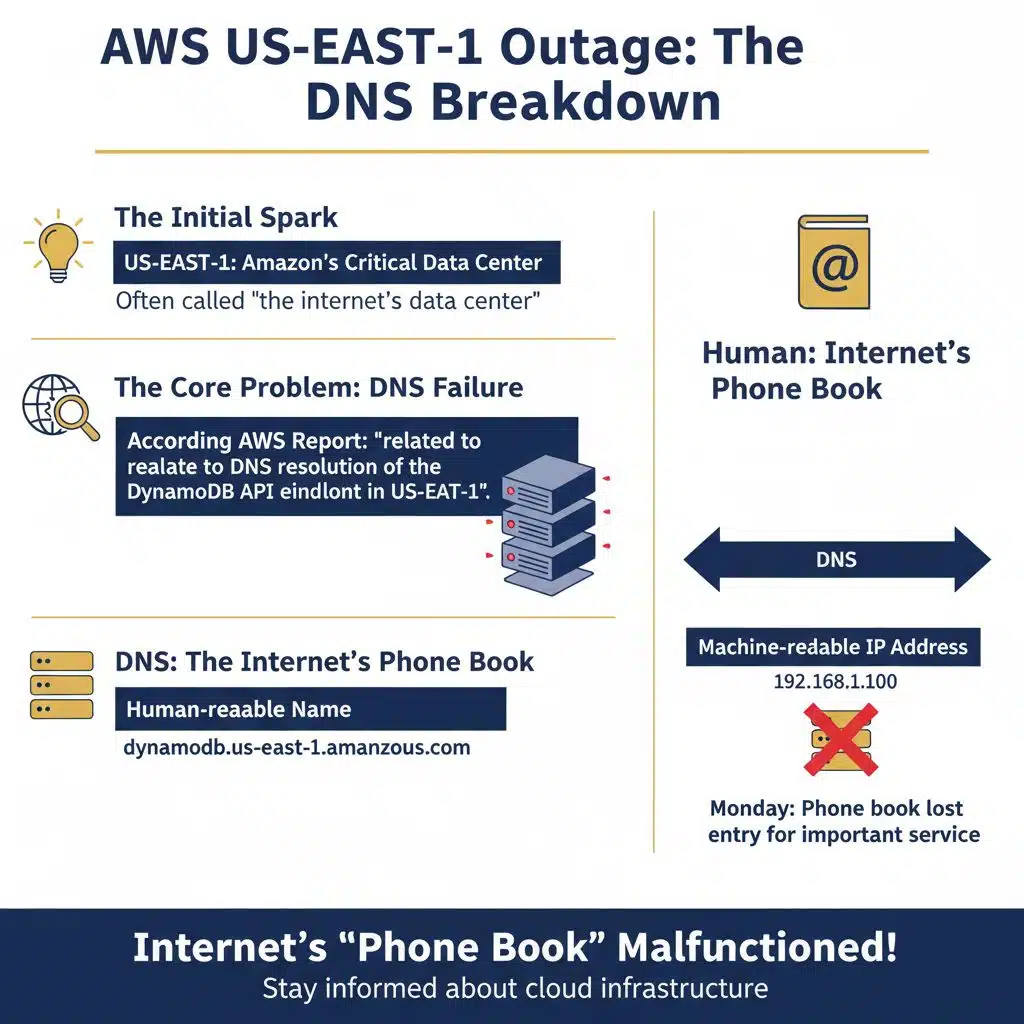
The problem began in US-EAST-1, Amazon’s oldest and most critical data region, often called “the internet’s data center.”
According to AWS’s own preliminary report, the outage was “related to DNS resolution of the DynamoDB API endpoint in US-EAST-1.
In simple terms, DNS is the internet’s phone book. It translates a human-readable name (like dynamodb.us-east-1.amazonaws.com) into a machine-readable IP address. On Monday, that phone book suddenly lost the entry for one of its most important services.
The Cascading Failure: Why One Error Crippled 37 Services
This “amnesia” created a devastating domino effect.
- Database Fails: Applications (like Snapchat) that tried to retrieve data (like a user’s login information) from DynamoDB could no longer find the database. Their requests failed, and users saw error messages.
- Compute Fails: Other services, like EC2 (the “brains” of an app), are designed to constantly check the health of their dependencies. When they could no longer get a healthy response from DynamoDB or the associated Network Load Balancers, they also began to fail.
- The System Halts: AWS’s internal monitoring systems, which are also built on AWS, were impacted. This chain reaction is a “cascading failure,” where one broken piece triggers a system-wide collapse.
The result was a total blackout for any application that relied on this combination of core services in US-EAST-1, which includes a significant portion of the entire internet.
Data & Timeline of the 15-Hour Meltdown
The outage was not brief. While AWS engineers detected the problem quickly, the recovery was a long, painstaking process of clearing backlogs and stabilizing systems.
Timeline of Events (October 20, 2025):
- ~12:11 AM PDT (07:11 GMT): AWS first registers “increased error rates and latencies” in US-EAST-1. The outage begins.
- ~12:26 AM PDT (07:26 GMT): AWS engineers identify the root cause as “DNS resolution issues” for DynamoDB.
- ~3:35 AM PDT (10:35 GMT): AWS reports the “underlying DNS issue has been fully mitigated,” but the recovery is just beginning. Services remain degraded as a massive backlog of requests must be processed.
- ~8:00 AM PDT (15:00 GMT): As the US West Coast woke up, outage reports spiked again, with millions unable to work or access services.
- 3:01 PM PDT (22:01 GMT): Nearly 15 hours after the event began, AWS updates its status to: “all AWS services returned to normal operations.
The scale of the impact was captured by outage trackers.
- Total User Reports: Downdetector, a site that monitors internet outages, received over 8.1 million user reports related to the AWS failure, including 1.9 million in the US and 1 million in the UK.
- AWS Services Impacted: At least 37 distinct AWS services were confirmed to be affected by the cascading failure, including Amazon Connect, Amazon CloudWatch, and AWS Lambda.
- Global App Failures: Reports showed a near-total blackout for services like Snapchat, Roblox, and Signal. Even the CEO of AI firm Perplexity, Aravind Srinivas, posted on X (formerly Twitter) to confirm: “Perplexity is down right now. The root cause is an AWS issue.
Expert Analysis: ‘A Single Point of Failure’
This event is the third major outage linked to the US-EAST-1 region in the last five years, prompting analysts to question the industry’s over-reliance on a single, albeit massive, provider.
Experts were quick to point out that this incident highlights a fundamental flaw in the internet’s architecture: centralization.
“Outages like this highlight a serious issue with how some of the world’s biggest companies often rely on the same digital infrastructure, meaning that when one domino falls, they all do,” said Marijus Briedis, CTO at NordVPN, in a statement.
The sentiment was echoed by UK experts, who noted the geopolitical and economic risk. Steven Murdoch, a professor of security engineering at University College London, told The Guardian the problem was an internal AWS accident, not a malicious attack, but the impact was just as severe.
Analysts at The Hindustan Times noted this event marked one of the largest internet breakdowns since the CrowdStrike incident last year, reminding the world that the global digital economy “runs on the cloud” and is vulnerable to “putting all economic eggs in one basket.
What to Watch Next: The Multi-Cloud Question
As services return to normal, the financial and reputational fallout is just beginning. AWS will be under immense pressure to release a detailed post-mortem explaining precisely how a DNS misconfiguration was allowed to propagate and take down its most critical region.
The primary discussion in boardrooms today will be about “multi-cloud” strategies—the practice of building applications that can run on more than one provider (like AWS, Microsoft Azure, and Google Cloud) to avoid a single point of failure.
While this approach adds significant cost and complexity, the 15-hour blackout on Monday provided a clear, multi-billion dollar argument for why it may be necessary. For now, the internet holds its breath, hoping the “amnesia” that struck US-EAST-1 does not become a recurring condition.
The Information is Collected from MSN and Yahoo.




































