Do your site updates break things, or take too long to test? If so, you are already living the problem this guide is built to solve: Understanding “Immutable Infrastructure” For Web Hosting means learning how to ship changes without slowly turning your servers into one-off mysteries.
Most outages I see in hosting stacks do not start with “bad code.” They start with drift, hotfixes, and midnight “just this once” changes. I’m writing this as an Acting Chief Technology Officer at Editorialge Media LLC with an engineering background, so I’m going to keep the ideas practical and decision-focused.
We’ll define immutable infrastructure, compare it to the “patch-in-place” model, walk through image-based deployment patterns (including blue/green and canary), then cover benefits, tradeoffs, and a tool stack you can actually run.
What Is Immutable Infrastructure for Web Hosting?

Immutable infrastructure replaces servers instead of changing them.
Immutable infrastructure means you build a new, versioned server image (or container image), deploy it, and then retire the old one. You do not patch live machines in place.
That one choice changes everything for web hosting: instead of guessing what is “really” running in production, you can point to an image ID and a commit. Your deployment process becomes “replace and verify,” not “tweak and hope.”
In a widely cited 2013 pattern write-up on “Immutable Server,” Martin Fowler’s site frames the idea as the logical next step after “phoenix servers”: once an instance is live, you stop making changes to it and ship updates by replacement.
- Build: Bake the OS, runtime, and baseline configuration into an image.
- Test: Validate the image in a staging environment that matches production.
- Deploy: Roll out the new image in controlled batches.
- Retire: Terminate the old instances so drift cannot accumulate.
Differences Between Mutable and Immutable Infrastructure
Mutable servers change over time. Admins patch, configure, and update live machines, which makes versioning and troubleshooting harder because “production” becomes a moving target.
Immutable systems replace images. You still change your infrastructure, but you change it through versioned artifacts and automated rollout, which keeps configuration consistent across a fleet.
| Decision Point | Mutable (patch in place) | Immutable (replace) |
|---|---|---|
| What you “deploy” | Commands and manual changes on a running server | Versioned images (VM images or containers) |
| Rollback | Undo steps, re-run scripts, or back out changes by hand | Re-point traffic to the prior image and retire the bad one |
| Drift risk | High, because every “small fix” can diverge | Low, because instances are short-lived and reproducible |
| Best fit | Legacy systems with heavy on-box state and low change cadence | Web apps, APIs, microservices, and autoscaled hosting |
Conceptual Differences: Pets vs. Cattle
“Pet” servers get careful, manual care. They have special tweaks, unique histories, and long lifespans, which is how mutable infrastructure quietly forms in the real world.
“Cattle” servers are meant to be interchangeable. If one gets sick, you replace it, which maps directly to immutable infrastructure.
- If you name servers or fear replacing them: you are in “pets” territory.
- If you can rebuild from code and images: you are operating a “cattle” model.
- Action for web hosting: remove “special access paths” (like ad hoc SSH fixes) and force changes through version control plus automated deployment.
- Operational win: on-call debugging gets simpler because the question becomes “which version is this?” not “what changed last week?”
Practical Differences: Snowflakes vs. Phoenixes
Snowflake servers are unique machines that admins change in place until nobody can reproduce them. That is usually where configuration drift and “works on one node” incidents come from.
Phoenix servers flip the mindset: you treat a server like a rebuildable unit. When you need a change, you rebuild the image and redeploy.
In that same 2013 “Immutable Server” pattern, the phoenix idea shows up as a stepping stone: automation helps you rebuild at will, then immutability removes the incentive to keep patching long-lived instances.
If a server has to be fixed by hand, it is telling you what needs to move into the image or the pipeline.
- Move config into code: store base configuration, build scripts, and environment templates in version control.
- Rebuild images for changes: treat OS updates, runtime updates, and app updates as a new artifact.
- Replace in batches: rollout safely, then terminate the old nodes to eliminate drift.
- Keep data out of the image: logs, uploads, and databases belong in managed services or external storage, not on “special” boxes.
How Does Immutable Infrastructure Work?
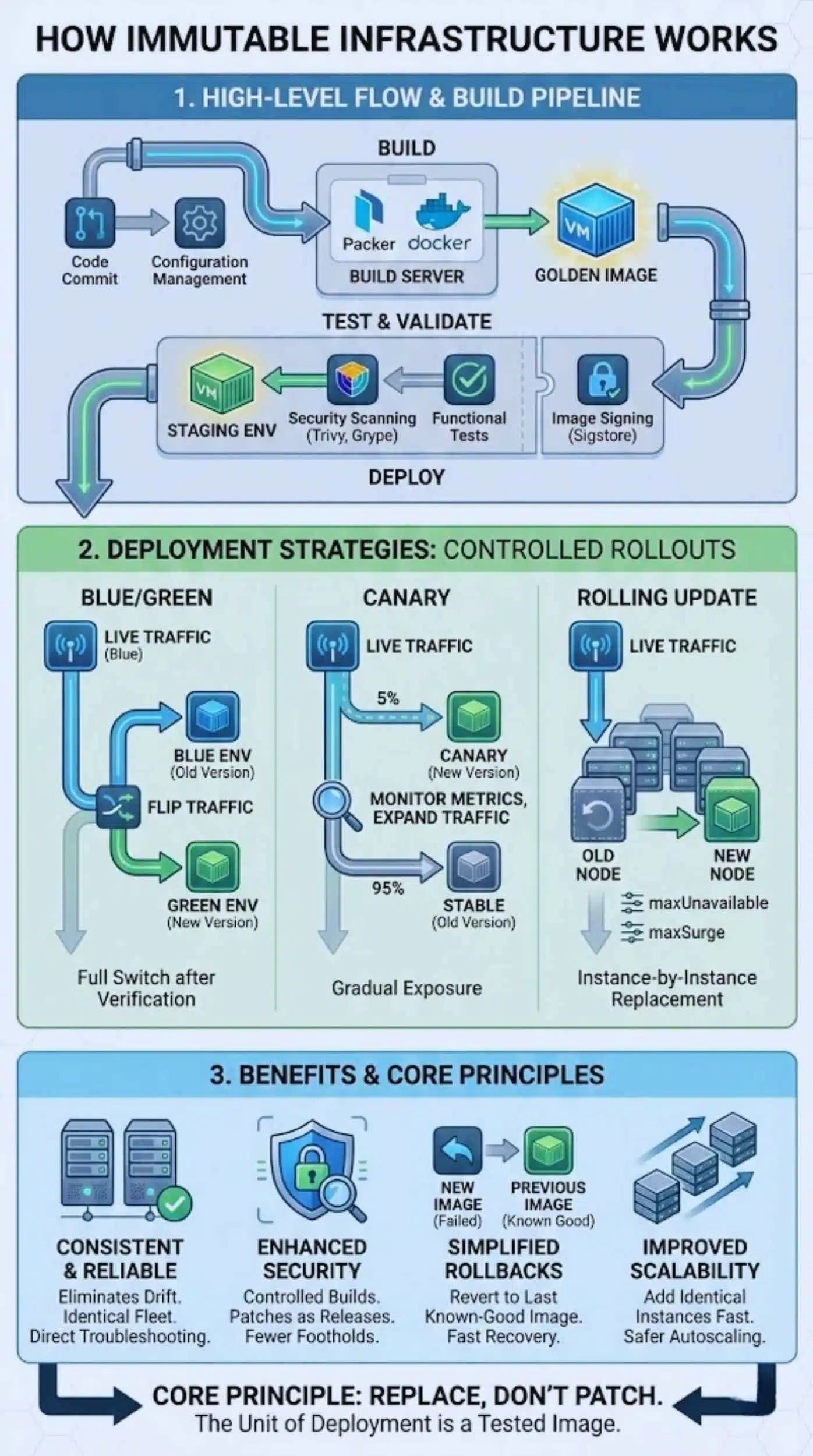
At a high level, immutable infrastructure works by turning servers into outputs of a build process. The “unit of deployment” is a tested image, not a live machine you edit.
For web hosting teams, the key is building a pipeline that can create images reliably and then roll them out with predictable traffic control.
Image-based Deployments
Image-based deployments start with a “golden image”: a machine image or container image that already contains the OS baseline, runtime, and your app build. HashiCorp describes Packer as a way to create identical machine images for multiple platforms from a single source template, which is exactly what you want for repeatable hosting.
In practice, you usually combine:
- Image build: Packer for VM images, or Docker builds for container images.
- Provisioning: Terraform to declare networks, load balancers, clusters, and scaling rules.
- Orchestration: Kubernetes (or a platform service) to handle rollout, health checks, and replacement.
- Validation: security scanning and basic smoke tests before traffic shifts.
For security scanning, tools like Trivy and Grype are commonly used to scan images for known vulnerabilities before you deploy them. For integrity, Sigstore Cosign supports signing container images, and its own guidance warns you to sign by digest rather than a mutable tag.
Blue/Green and Canary Deployments
Immutable infrastructure really pays off when you pair it with progressive delivery, so you can replace infrastructure while controlling blast radius.
| Strategy | What happens | Best use in web hosting |
|---|---|---|
| Blue/Green | Run two environments, switch traffic from old to new once the new side is verified. | Major releases, framework upgrades, or migrations where you want a clean cutover. |
| Canary | Send a small slice of traffic to the new version, watch metrics, then expand. | High-traffic sites where you want early warning before full rollout. |
| Rolling update | Replace instances gradually, keeping service available during the rollout. | Steady, frequent releases where you want controlled churn. |
In Kubernetes, the official Deployment documentation explains that rolling updates are controlled by maxUnavailable and maxSurge, with a default maxUnavailable of 25%. That default is a good reminder: replacements can temporarily increase capacity or reduce availability unless you set clear rollout limits.
- Blue/green: validate the “green” side end-to-end, then flip the service or load balancer to send production traffic to green.
- Canary: start small and promote only if your error rate, latency, and resource usage stay stable.
- Fast rollback: keep the previous image ready so you can revert by swapping back, not by patching forward.
- Do not guess with traffic: define health checks and concrete thresholds (5xx rate, p95 latency, saturation) before you ship.
Benefits of Immutable Infrastructure
Immutable infrastructure speeds deployment and keeps configurations consistent. It improves security, simplifies rollbacks, and supports scalability through automation and version control.
The teams that benefit most treat immutability as a workflow, not a buzzword: image builds, repeatable deployment, and disciplined replacement.
Consistent and Reliable Deployments
Replacing servers instead of changing them stops configuration drift. Every node in the fleet starts from the same known baseline.
This also makes troubleshooting more direct: you can correlate incidents to a specific image version, not a pile of undocumented edits.
- Less “it depends” debugging: identical images reduce hard-to-reproduce bugs.
- Cleaner handoffs: your runbooks can reference versions, not tribal knowledge.
- More confidence in automation: once you trust the pipeline, you stop fearing deployments.
Enhanced Security
Immutable infrastructure raises security by moving change into a controlled build process. You rebuild images with updates, test them, then replace instances, which reduces the temptation to “quick patch” a single server and forget what happened.
For containerized hosting, NIST’s Application Container Security Guide highlights risks like vulnerable or stale images and clear-text secrets embedded in images, then recommends controls such as vulnerability management, secure configuration, and keeping secrets out of images.
- Patch management becomes a release: you can schedule image rebuilds for OS and runtime updates, then roll them out safely.
- Fewer long-lived footholds: compromised instances get replaced rather than “cleaned up” by hand.
- Better guardrails: scanning and signing images helps you prevent unknown or tampered artifacts from reaching production.
Simplified Rollbacks and Updates
Rollbacks are simpler because you revert to a prior, known-good image. You do not try to reverse a chain of in-place edits.
This is where immutable infrastructure supports DevOps outcomes directly. DORA’s research has continued refining how teams measure delivery, and as of a January 2026 update on DORA’s metrics history, “failed deployment recovery time” is explicitly framed around restoring service after a change, which aligns neatly with image-based rollback.
If rollback requires “fixing the server,” you are still operating a mutable system in disguise.
Improved Scalability
Immutable infrastructure scales by adding more identical instances fast. Instead of nursing one box into place, you replicate a tested image across a fleet.
Cloud platforms have native mechanics that match this idea. For example, Amazon EC2 Auto Scaling’s documentation describes “instance refresh” as a way to replace instances in batches, with controls like minimum healthy percentage, warmup, and rollback support.
- Autoscaling is safer: new nodes match the same baseline, so scale events do not introduce surprise differences.
- Traffic spikes get simpler: you can add capacity without inventing new server configurations on the fly.
- Predictable limits: rollout settings (surge and unavailable counts) let you balance speed and availability.
Challenges and Considerations
Immutable infrastructure can raise initial setup costs, and it demands strong skills in automation and Infrastructure as Code. Teams must adapt deployment workflows and version control habits, and there is a real learning curve.
The tradeoff is usually worth it for web hosting, but it is still a tradeoff, so you want to plan it instead of discovering it mid-incident.
Higher Initial Setup Costs
The up-front work comes from building image pipelines, wiring CI, and defining infrastructure in code. You are paying in engineering time so you can stop paying in firefighting later.
There can also be real runtime cost during rollouts. Microsoft’s guidance on Virtual Machine Scale Sets notes that MaxSurge upgrades create new instances to replace old ones, which helps keep capacity stable but consumes extra quota. Google’s managed instance group documentation makes a similar point: higher surge settings speed updates, but you are billed for the additional instances.
- Plan capacity for deployments: decide how much surge your hosting budget can tolerate.
- Keep images lean: the more you pack into a base image, the slower rebuilds and troubleshooting become.
- Separate base and app images: update OS baselines on a cadence, update app layers as often as you ship.
Learning Curve for Teams
Immutable infrastructure changes how people think. Engineers stop “fixing servers” and start “fixing the pipeline,” which can feel slower until the team builds muscle memory.
The most overlooked step, in my experience, is agreeing on what is allowed to change at runtime. If you let teams quietly sneak fixes onto boxes, you will get drift again, just with nicer tooling.
- Define a no-manual-change rule: emergencies still happen, but every manual fix must turn into a pipeline change within a day or two.
- Standardize versioning: image IDs, release tags, and infrastructure modules should map back to commits.
- Practice replacements: run “replace a node” drills during calm weeks, not during outages.
- Teach the patterns: blue/green, canary, and rolling updates all look similar until you operate them under pressure.
Applications of Immutable Infrastructure in Web Hosting
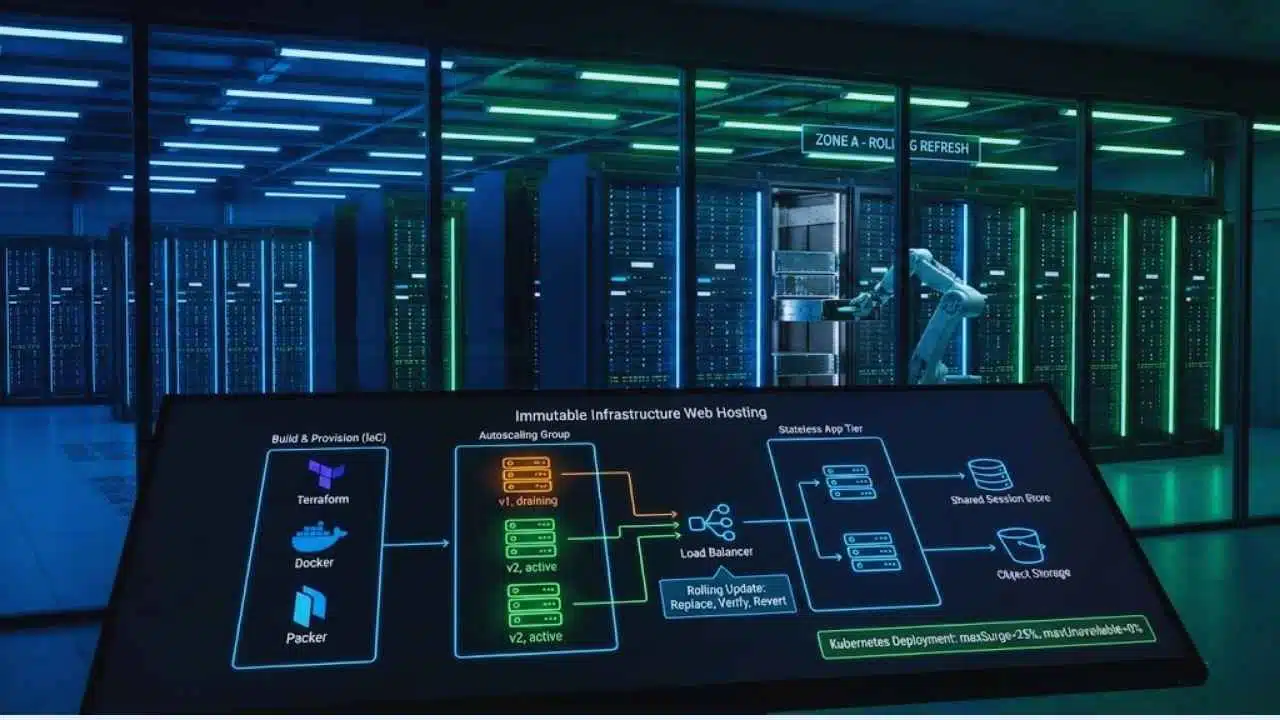
Immutable infrastructure fits web hosting because most hosting workloads scale horizontally and benefit from predictable, repeatable nodes.
The strongest use cases are platforms that autoscale, and stateless applications that can tolerate instance replacement without losing critical data.
Hosting Platforms with Automated Scaling
Major cloud hosting platforms support replacement-oriented workflows. On AWS, instance refresh can replace Auto Scaling group instances in batches and can roll back a refresh when it fails, which matches the immutable approach of “replace, verify, revert if needed.”
On Google Cloud, managed instance groups can proactively roll out configuration updates and support canary-style updates to a subset of instances. On Azure, scale set rolling upgrades with MaxSurge replace instances by creating new ones, so capacity can remain steady during the upgrade.
- For a classic web tier: put stateless app servers behind a load balancer and replace them through your rollout tool.
- For Kubernetes hosting: treat nodes as replaceable and let the scheduler resettle pods after node rotation.
- For multi-region hosting: rollout one region at a time so you contain risk and keep a stable fallback.
Deployment of Stateless Applications
Stateless apps are the cleanest match for immutability. If the instance can disappear without losing customer data, replacement becomes an everyday operation instead of a scary event.
Kubernetes Deployments support rolling updates with configurable surge and unavailable limits, which makes it practical to rotate versions frequently while keeping the service up.
- Externalize sessions: store sessions in a shared store so instance replacement does not log users out unexpectedly.
- Externalize uploads: store user uploads in object storage, not on local disks.
- Keep migrations deliberate: pair app rollouts with backwards-compatible database changes, then clean up later.
- Design for replacement: assume any instance can be terminated at any time, because autoscaling and failures will do it anyway.
Tools for Implementing Immutable Infrastructure
You do not need a complicated stack, but you do need clear roles: one layer builds artifacts, one layer provisions infrastructure, and one layer orchestrates rollout.
Choose tools that let you define infrastructure as code, automate deployments, and version configurations, so updates stay repeatable for web hosting.
Infrastructure as Code (IaC) Tools
Terraform is a common choice because it standardizes provisioning across providers and treats infrastructure definitions as a system of record. HashiCorp positions Terraform as a single workflow to provision and manage infrastructure across environments, which matters when you want the same deployment pattern across dev, staging, and production.
- Use modules: standardize “web tier,” “database tier,” and “network” patterns so teams stop inventing infrastructure from scratch.
- Review plans: make infrastructure changes visible before they apply.
- Keep drift visible: run regular checks so “temporary” changes do not become permanent mysteries.
Containerization Platforms
Containerization makes immutability more natural because the application runtime ships as an image. Kubernetes then orchestrates rollout, scaling, and self-healing, which reduces manual server management.
Kubernetes Deployments also expose concrete rollout controls (maxSurge and maxUnavailable). Treat those as business levers: faster rollout increases risk and cost, slower rollout reduces risk but delays delivery.
| Need | Practical tool choices | What to standardize |
|---|---|---|
| Build images | Packer (VM images), Docker (container images) | Base image, hardening, patch cadence |
| Provision infrastructure | Terraform (IaC) | Networks, clusters, load balancers, autoscaling rules |
| Orchestrate rollout | Kubernetes | Health checks, rollout limits, rollback steps |
| Reduce supply chain risk | Trivy or Grype (scanning), Cosign (signing) | Scan gates, signed artifacts, pinned versions |
Final Thoughts
Understanding “Immutable Infrastructure” For Web Hosting starts with one practical rule: replace servers, do not patch them. Once you build around versioned images, automation, and Infrastructure as Code, you get consistency in deployment, faster rollbacks, and simpler server management.
This approach supports scalability and stronger security habits, and it fits naturally with DevOps, containerization, and cloud computing. If you want a clean next step, pick one web tier, build an image pipeline for it, and practice safe replacement until it feels routine.