Beyond The Benchmarks: What DeepSeek-Coder V2 vs GitHub Copilot Really Means For AI Coding In 2026
DeepSeek-Coder V2 vs GitHub Copilot is suddenly the wrong “who’s better?” question and the right “where’s the moat?” question. With Copilot shifting toward agents and multi-model routing in 2026, DeepSeek’s open weights test whether coding intelligence is commoditizing faster than the products built on top of it.
Key Takeaways
-
DeepSeek-Coder V2 shows top-tier coding performance can be delivered with open weights and efficient Mixture-of-Experts design, shrinking the “closed-only” advantage in code tasks.
-
GitHub Copilot’s edge is increasingly product-shaped, not model-shaped: distribution (GitHub), enterprise governance, and workflow automation (agents) matter more as raw coding quality converges.
-
The competitive battleground is moving from “best autocomplete” to “best software engineer loop”: editing, testing, review, deployment, and security across a repo.
-
A trust gap is widening: developer AI adoption is high, but confidence is falling, making verification and secure-by-design tooling the next decisive differentiator.
-
Copilot’s 2026 pivot toward multiple frontier models (not just one) suggests Microsoft and GitHub expect model commoditization and are building a “router + workflow” platform to stay ahead.
-
“Better” depends on procurement reality: open models win on sovereignty and customization, while Copilot wins on integration, compliance, and end-to-end productivity for most enterprises.
How We Got Here: From Autocomplete To Agentic Development
Two years ago, the defining question for AI coding tools was simple: can the model write correct code from a prompt? In 2026, that framing is outdated. Coding assistants are being judged by whether they can operate inside real repositories with messy dependencies, partial context, flaky tests, and human teams.
Microsoft’s earnings commentary signals this shift. GitHub Copilot is no longer described as a suggestion engine. It is pitched as “Agent Mode” plus new “form factors like Coding agent,” alongside code review at massive scale. That language matters because it implies a business thesis: the next phase is workflow automation and platform leverage, not incremental completion quality.
At the same time, GitHub’s Octoverse reporting underscores how fast AI moved from novelty to baseline expectation. GitHub ties a step-change in developer sign-ups to the launch of Copilot Free in late 2024 and reports that nearly 80% of new developers use Copilot within their first week. In other words, Copilot is becoming part of the default onboarding experience for coding.
Then DeepSeek-Coder V2 lands as a direct challenge to the idea that only closed models can do this well. Its technical report argues that an open, code-specialized Mixture-of-Experts model can match or beat several closed systems on a range of coding tasks, including repair-style benchmarks that resemble real work.
So the strategic question becomes: if strong coding intelligence is increasingly available as a model commodity, what decides winners? The answer is likely to be integration, trust, governance, and economics.
A Quick Timeline Of The Inflection Points
| Date | What Changed | Why It Mattered |
|---|---|---|
| Late 2024 | Copilot Free launches | Expanded Copilot’s funnel and made AI-assisted coding default for new GitHub developers. |
| March–April 2025 | Copilot coding agent preview and Copilot code review arrive | Signaled shift from suggestions to autonomous or semi-autonomous workflow steps. |
| July 30, 2025 | Microsoft says Copilot hits 20M users; enterprise customers +75% QoQ; 90% of Fortune 100 use it | Demonstrated product-market fit at enterprise scale and made Copilot a platform asset. |
| Oct–Nov 2025 | Octoverse links AI and typed languages; highlights explosive activity | Reinforced that AI is reshaping how and what developers ship, not just speed. |
| Mid–late 2025 into 2026 | Copilot expands to multiple frontier models and introduces “premium requests” billing | Indicates model abundance and rising cost controls; Copilot becomes a model router with governance. |
What DeepSeek-Coder V2 Actually Is And Why It Landed So Hard
DeepSeek-Coder V2 is not “just another coder model.” It is a statement about efficiency and openness.
The model family uses a Mixture-of-Experts approach, which is crucial in 2026 economics. MoE systems keep total parameter counts high while activating only a smaller subset per token. In DeepSeek’s report, the larger model is listed at 236B total parameters with 21B active parameters. That “active” number is the practical clue: you can get strong performance without paying the full inference cost of a dense 200B+ model on every token.
The report also emphasizes long-context coding, extending context length up to 128K. In real development, this matters because repository-level tasks are context-hungry: config files, dependency graphs, test suites, and prior commit history quickly exceed typical chat windows.
Unlike many frontier-grade systems, DeepSeek’s weights are distributed openly for research and development use with an explicit commercial-use allowance (subject to license terms). That availability changes the procurement equation for companies that cannot or will not send proprietary code to a third-party SaaS.
DeepSeek-Coder V2 In Numbers

| Model | Total Parameters | Active Parameters | Practical Implication |
|---|---|---|---|
| DeepSeek-Coder-V2-Lite | 16B | 2.4B | Low “active” footprint makes local or cost-sensitive deployment more realistic. |
| DeepSeek-Coder-V2 | 236B | 21B | Frontier-like capability with MoE efficiency, designed for long-context repo work. |
Why this matters: DeepSeek is attacking a core assumption in the Copilot era, namely that the best coding intelligence must be accessed as a hosted, closed model. If open MoE models keep improving, pricing power shifts away from model vendors and toward workflow platforms.
The Benchmarks That Matter Now Are The Ones That Look Like Work
A quiet but huge shift is happening in how coding assistants are evaluated. Traditional generation benchmarks (write a function, solve a puzzle) still matter, but they are no longer the full story. Repair and editing benchmarks are more predictive of day-to-day engineering value because most professional coding is modification, not greenfield creation.
DeepSeek’s headline is not only HumanEval or MBPP scores, although it posts strong numbers there (HumanEval 90.2, MBPP+ 76.2). The bigger signal is repair-style performance, where the model has to understand a codebase and produce a patch that survives tests.
In DeepSeek’s own repair benchmark reporting, DeepSeek-Coder-V2-Instruct scores 73.7% on Aider’s code editing benchmark and 12.7% on SWE-Bench, while also reaching 21.0% on Defects4J. The key competitive point is the Aider score in their reported comparison set, where the model is positioned as ahead of other listed systems at the time of reporting.
Repair Performance Snapshot
| Model | Defects4J | SWE-Bench | Aider |
|---|---|---|---|
| DeepSeek-Coder-V2-Instruct | 21.0% | 12.7% | 73.7% |
| GPT-4o-0513 | 26.1% | 26.7% | 72.9% |
| GPT-4-1106 | 22.8% | 22.7% | 65.4% |
| Claude-3-Opus | 25.5% | 11.7% | 68.4% |
| Gemini-1.5-Pro | 18.6% | 19.3% | 57.1% |
The important nuance: these are benchmark slices, not guarantees. But they reveal the strategic direction of travel. If open models can be close enough on repo-like tasks, then Copilot’s defensibility cannot rest on raw model quality alone.
“Better Than Copilot” Depends On Whether You Mean Model Or Product
DeepSeek-Coder V2 is a model you can deploy. GitHub Copilot is a product platform that can swap models, govern usage, and embed itself into the software lifecycle.
Microsoft’s messaging points to Copilot’s value being systemic: agent mode, coding agents, and code review agents operating at massive scale. That is a workflow layer wrapped around model outputs, and it is also a data flywheel because it lives where code is written, reviewed, and merged.
By 2026, Copilot looks less like “one vendor’s model” and more like a multi-model cockpit. Product updates increasingly emphasize model choice and access to multiple frontier systems, shaped by plan tiers and usage allowances.
This changes the competitive lens: even if DeepSeek-Coder V2 beats a given model on a benchmark, Copilot can respond by routing users to the best model for a given task, then monetizing the higher-cost calls through premium request accounting.
What “Better” Means Across Real Buyer Criteria
| Decision Factor | DeepSeek-Coder V2 Tends To Win When… | GitHub Copilot Tends To Win When… |
|---|---|---|
| Data Sovereignty | You need self-hosting and tighter control over source code exposure. | You accept SaaS controls and want managed governance at scale. |
| Workflow Integration | You can build your own IDE + CI hooks, or you already have an internal dev platform team. | You want immediate IDE integration plus agents and code review built into the ecosystem. |
| Model Agility | You can swap models freely and tune for your domain. | You want access to multiple frontier models without managing infra. |
| Cost Control | You can exploit MoE efficiency and run inference where it is cheapest for you. | You prefer predictable per-seat pricing, then pay more only for premium usage. |
| Compliance And Audit | You can implement internal logging, access control, and policy enforcement. | You want vendor-provided enterprise controls and billing governance. |
Bottom line: DeepSeek can be “better” as a model, especially where self-hosting, customization, or cost efficiency dominate. Copilot can be “better” as a system because it wraps models inside a product and governance architecture that most companies do not want to rebuild.
The Economics: Why Open MoE Models Threaten The Per-Seat Status Quo
AI coding assistants are moving into a classic pattern: model quality rises, marginal costs fall, and differentiation shifts to packaging.
DeepSeek’s MoE design is a direct bet on this. The report emphasizes strong results with only 21B active parameters in the large model. For buyers, active parameters translates into inference cost pressure. If comparable coding quality can be served with lower active compute, then the cost floor drops.
Copilot’s response is telling: it is not only expanding model options, it is also tightening unit economics through premium request accounting. In practice, that is what you do when model costs remain material and usage is growing.
At the enterprise level, pricing is explicit: Copilot Business is commonly priced at $19 per user per month and Copilot Enterprise at $39 per user per month. Predictability is part of the value. But it also creates an opening: if open models reduce costs enough, some organizations will ask why they should pay a recurring seat fee for what they see as a commodity capability.
The Pricing And Governance Tradeoff
| Approach | Direct Cost Model | Hidden Cost Model | Who Usually Chooses It |
|---|---|---|---|
| Copilot Business / Enterprise | $19 or $39 per user per month | Premium usage, plus organizational change management and training. | Companies prioritizing speed-to-value and standardized controls. |
| Self-Hosted DeepSeek-Coder V2 | Compute, infra, and ops | Engineering time to integrate, govern, and maintain, plus evaluation and security hardening. | Companies prioritizing sovereignty, customization, or cost optimization at scale. |
Why this matters in 2026: the market is starting to split. One segment buys “AI development as a managed service.” The other buys “AI development as infrastructure,” increasingly powered by open models.
Trust Is Becoming The Real Bottleneck
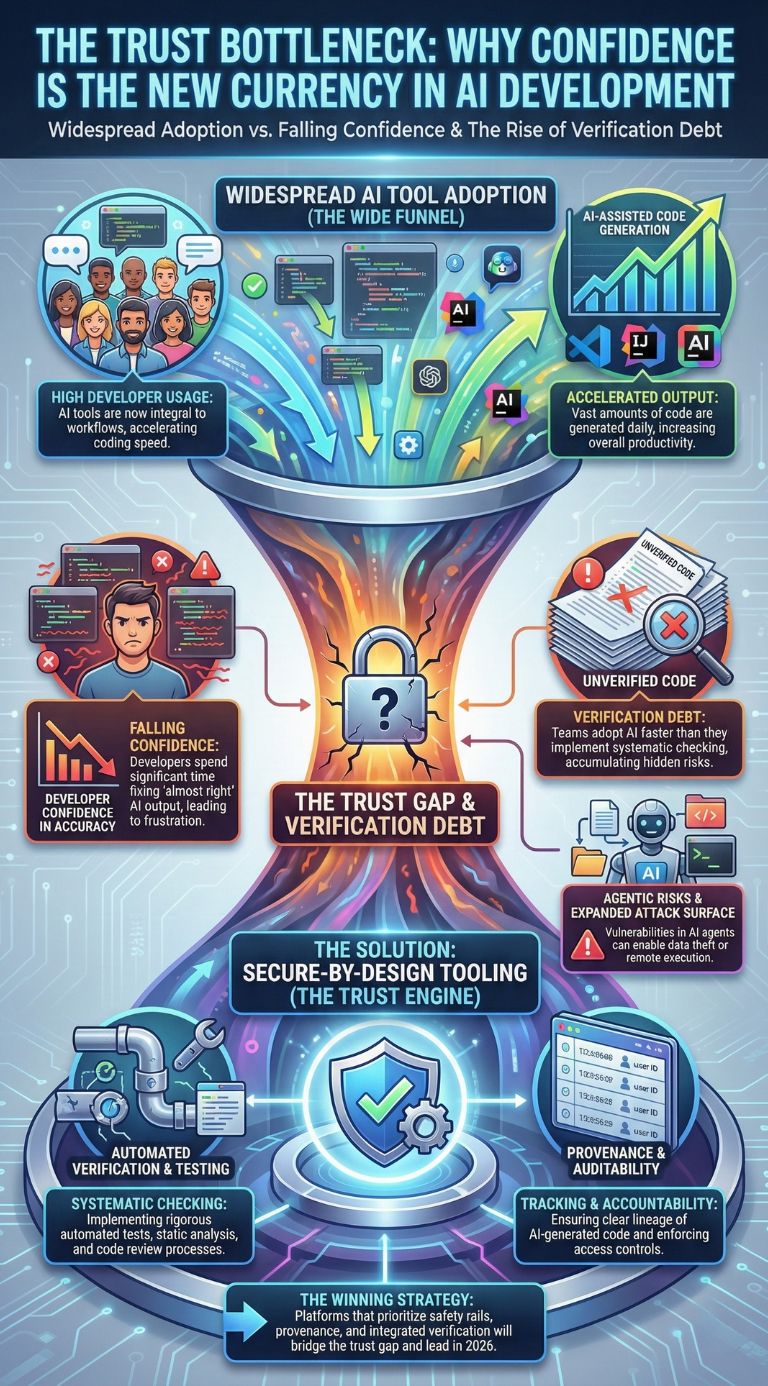
If you want the most predictive statistic about who wins the next phase, it might not be a benchmark at all. It might be trust.
Developer survey coverage in late 2025 shows a sharp pattern: AI tool usage is widespread, but trust in accuracy is low. Many developers report spending significant time fixing “almost right” AI output, especially when the assistant produces plausible code that fails in edge cases.
Industry reporting in late 2025 and early 2026 also warns about “verification debt,” meaning teams adopt AI faster than they adopt systematic checking practices. Whether every organization experiences it equally, the direction is consistent: AI accelerates typing, but it can also accelerate subtle mistakes.
Security concerns rise further with agentic tooling. Reports about vulnerabilities affecting AI-assisted IDE workflows reinforce that the attack surface expands when tools can read files, run commands, and interact with developer environments. That risk is not theoretical for enterprises that ship sensitive code.
This is where the DeepSeek vs Copilot debate flips: as models get better, the high-stakes differentiator becomes the safety rails and verification tooling around them. Copilot is positioning itself as that managed environment. DeepSeek gives you the engine, but you are responsible for the brakes.
A Trust And Risk Snapshot
| Signal | What The Data Suggests | Why It Changes Buying Behavior |
|---|---|---|
| AI Tool Usage Is Widespread | Most developers now use AI tools in workflows | Adoption is no longer the hard part. Governance is. |
| Trust Is Falling | Confidence in AI accuracy remains low | Teams will demand verification, testing, and provenance features. |
| Agentic Workflows Expand Attack Surface | IDE and agent vulnerabilities can enable data theft or RCE | “Secure for AI” design becomes a differentiator for platforms. |
GitHub’s Distribution Advantage Is Still Massive
Even if open models narrow the intelligence gap, GitHub starts from a structural advantage: it is where developers already are.
GitHub’s own reporting highlights platform scale in developers and repository activity, and also links the availability of a free Copilot tier to faster onboarding and early usage. That matters because it creates a platform feedback loop.
Copilot is embedded in IDEs and GitHub workflows. That increases usage and creates more opportunities for product refinement. GitHub can package features, like code review agents, where the work already happens.
DeepSeek can win model comparisons and still lose the market if it cannot match distribution and workflow gravity. The open ecosystem can partially compensate via integrations and internal platforms, but that path is slower and more fragmented.
Expert Perspectives: Three Competing Theses About What Wins Next
Model Quality Is The Moat
This camp argues better models always win because better code suggestions and better repo edits compound into productivity. DeepSeek’s reported repair and editing results support the idea that model quality still moves the needle, especially for long-context tasks.
Counter-argument: Copilot’s multi-model posture suggests GitHub agrees quality matters, but expects it to be sourced from multiple vendors rather than owned by one.
Workflow Is The Moat
This camp argues developers pay for outcomes, not architecture. Copilot’s pitch is exactly that: agents, code review at scale, and enterprise-standard governance, wrapped into the GitHub ecosystem.
Counter-argument: if open models make it cheap to replicate “good enough” workflow features, the platform moat narrows.
Trust And Governance Become The Moat
This camp focuses on the trust gap. If confidence is falling while usage rises, teams will demand verification, auditability, and secure agent boundaries. In that world, the winning platform is the one that makes it easy to be safe.
Counter-argument: enterprises can build governance around open models too, but it requires maturity and staffing many teams do not have.
What Happens Next: The Milestones To Watch In 2026
-
Agent reliability becomes the headline metric. Expect more emphasis on repo-level success rates: passing tests, clean diffs, safe dependency updates, and measurable reduction in review cycles.
-
Premium usage models spread. Usage allowances and premium accounting are strong indicators that “one seat, unlimited frontier compute” is unlikely to hold as agentic usage grows.
-
Open models push self-hosted copilots into the mainstream. MoE efficiency and commercial-use allowances reduce friction for internal deployments, especially in regulated industries.
-
Trust tooling becomes a purchasing line-item. Buyers will push for provenance, sandboxing, policy enforcement, logging, and secure-by-default IDE integrations.
-
The “better than Copilot” debate becomes a segmentation story. For some teams, DeepSeek-like models will be the foundation. For others, Copilot-like platforms will remain the default.
Final Thoughts: Is DeepSeek-Coder V2 Finally Better Than GitHub Copilot?
DeepSeek-Coder V2 is “better” if your definition is model capability per dollar, long-context repo reasoning, and the strategic freedom that comes with open weights and self-hosting options. Its reported repair and editing performance is a signal that open models can compete near the frontier in practical developer work.
GitHub Copilot is “better” if your definition is shipping software inside teams at scale, with governance, multi-model access, and workflow automation layered into the place where most code already lives. Microsoft’s reported traction and Copilot’s agent direction make the platform advantage real.
The most important takeaway is the strategic shift: DeepSeek-Coder V2 makes it harder for any vendor to claim durable advantage purely from having a better model. In 2026, the winners are likely to be the systems that solve trust, verification, integration, and economics end-to-end.