The cloud as we know it is changing. For years, “serverless” meant spinning up containers in a centralized data center—typically strictly defined by regions like us-east-1. While this revolutionized infrastructure management, it still left a gap in performance: physics. No matter how fast your code executes, if your user is in Tokyo and your function is in Virginia, latency is inevitable.
Enter Serverless 2.0. This isn’t just an incremental update; it is a fundamental architectural shift from centralized clouds to edge-native applications. By pushing compute power out of massive data centers and onto the edge of the network—literally closer to the user—Serverless 2.0 is redefining what we consider “fast” on the web.
Key Takeaways
- Geography is the New Optimization: The biggest performance bottleneck today isn’t code efficiency; it’s the physical distance between the user and the server. Serverless 2.0 solves this by bringing compute to the user.
- Cold Starts Are History: Modern edge runtimes use lightweight isolates that start in microseconds, eliminating the “spin-up” lag associated with traditional containers.
- Hybrid Architectures Will Dominate: Most applications won’t go 100% edge immediately. The winning pattern for the next few years will be “Edge for interaction, Cloud for storage,” combining the speed of Serverless 2.0 with the consistency of centralized databases.
- The “Dumb Pipe” Era is Over: CDNs are no longer just for static images. They are now intelligent, programmable platforms capable of running complex logic, AI inference, and dynamic personalization.
- User Experience = Revenue: In a competitive digital landscape, the speed gains provided by edge computing directly correlate to higher conversion rates and better user retention.
What Is Serverless 2.0?
Serverless 2.0 represents the convergence of serverless logic and edge computing networks.1 It moves beyond the “pay-for-what-you-use” model of traditional FaaS (Function-as-a-Service) to a “run-where-the-user-is” model.
From Traditional Serverless to Edge-Native Execution
The first wave of serverless, popularized by the launch of AWS Lambda in 2014, solved the problem of server management, Developers could deploy code without provisioning EC2 instances. However, these functions still lived in centralized availability zones. If a user in London accessed an app hosted in Oregon, the request had to travel halfway around the world and back.
Serverless 2.0 decouples code from specific regions entirely. In this distributed cloud architecture, code is replicated across hundreds of locations globally. When a request comes in, the network automatically routes it to the nearest available node, slashing latency from hundreds of milliseconds to double digits.
Key Characteristics of Serverless 2.0
- Ultra-low Latency: Execution happens milliseconds away from the user.
- Global by Default: No need to select a “region”; the code exists everywhere simultaneously.
- Instant Cold Starts: Unlike the heavy containers of Serverless 1.0, edge runtimes (often built on V8 isolates) spin up in microseconds.
- Standardized Web APIs: Many edge platforms utilize standard Web APIs (Fetch, Request/Response), making code more portable.
Understanding Edge Computing in Simple Terms

To grasp the power of Serverless 2.0, we must look at the infrastructure powering it: the Edge.
How Edge Computing Works
Traditionally, Content Delivery Networks (CDNs) were used only for static assets—images, CSS, and video files. They cached this content on servers all over the world so it could be downloaded quickly.
Edge computing turns these CDN nodes into intelligent compute platforms. Instead of just delivering a static file, the edge node can now execute logic, query databases, and manipulate data. It transforms the “dumb pipe” of content delivery into a smart, programmable network.
Edge vs. Centralized Cloud Infrastructure
In a centralized cloud model, data follows a long path:
User Device -> ISP -> Backbone Network -> Data Center (Compute) -> Database -> Return Path.
Each “hop” adds latency.
In an edge-native model, the path is drastically shortened:
User Device -> ISP -> Local Edge Node (Compute) -> Return Path.
By processing requests at the edge of the network, we eliminate the bulk of the travel time, resulting in snappy, near-instant user experiences.
Why Speed Matters More Than Ever
In the digital economy, speed isn’t just a technical metric; it’s a business requirement.
Latency, User Experience, and Conversion Rates
Performance is the backbone of user retention.5 Studies consistently show that bounce rates spike significantly if a page takes longer than 3 seconds to load.6 In the era of Serverless 2.0, users expect real-time interactions. Whether it’s an eCommerce checkout or a dashboard update, delays are perceived as broken functionality.
The Cost of Milliseconds in Modern Applications
For certain industries, latency is a direct revenue killer:
- Gaming: In multiplayer games, high latency (lag) destroys the competitive integrity of the match.
- Fintech: High-frequency trading and fraud detection rely on sub-millisecond processing to authorize transactions before they complete.
- AI Inference: Chatbots and recommendation engines need to process inputs and return answers instantly to feel “intelligent.”
How Edge Computing Redefines Serverless Performance
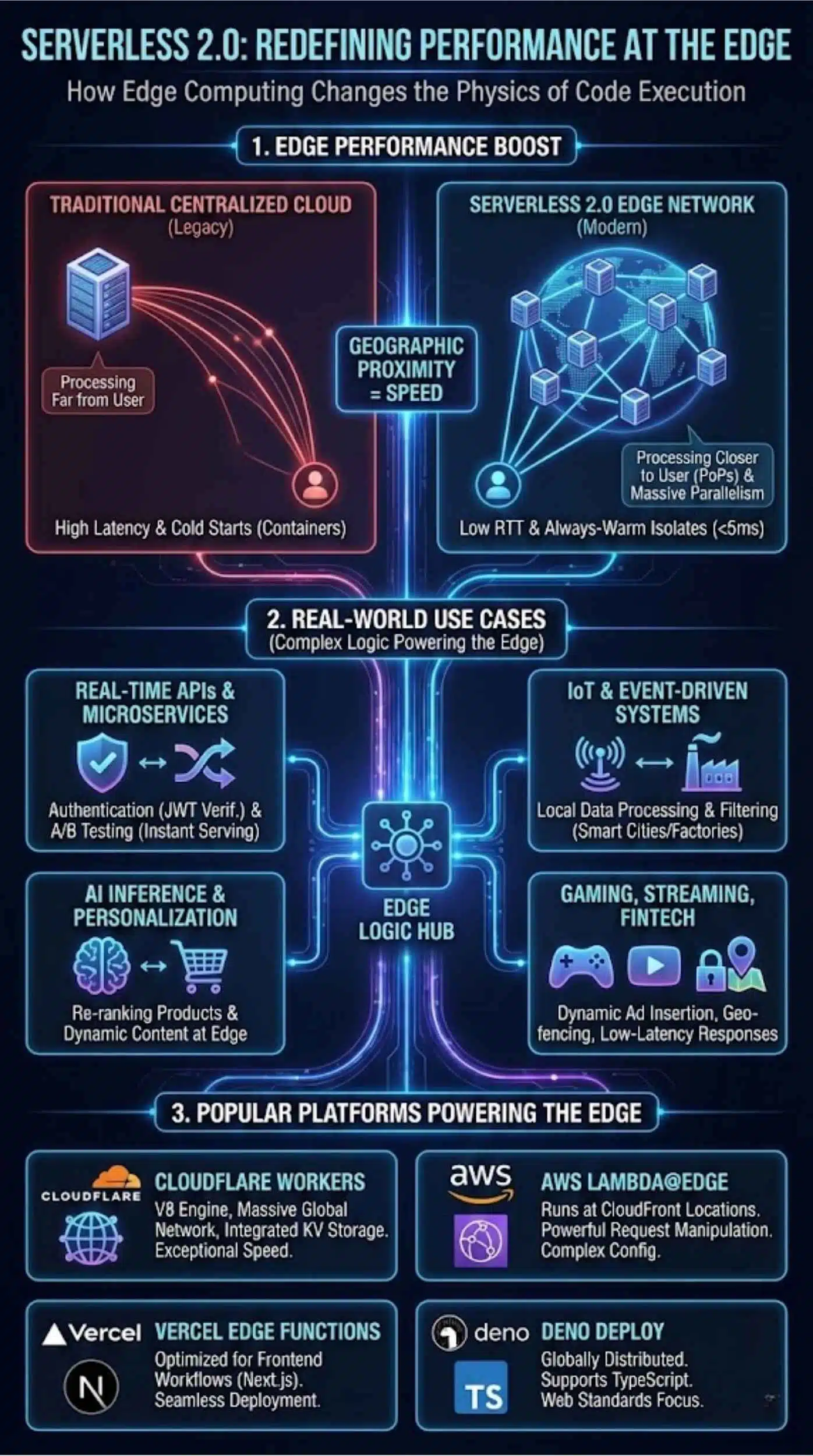
Serverless 2.0 changes the physics of how code runs on the internet.
Executing Code Closer to the User
The primary performance boost comes from geographic proximity. Platforms like Cloudflare Workers or Deno Deploy run on networks with points of presence (PoPs) in hundreds of cities.8 A user in Mumbai hits a server in Mumbai, not Frankfurt. This reduces the Round Trip Time (RTT), which is the single biggest contributor to perceived slowness.
Cold Starts vs. Always-Warm Edge Functions
One of the biggest complaints about traditional serverless (like early AWS Lambda) was the “cold start”—the delay that occurred while the cloud provider provisioned a container for dormant code.9
Serverless 2.0 largely mitigates this by using lightweight isolates rather than full containers or virtual machines. These isolates share a single runtime engine and can startup in under 5 milliseconds. This makes edge functions feel “always-warm,” even if they haven’t been called in hours.
Parallel, Globally Scaled Execution
Edge networks are inherently distributed.10 This allows for massive parallelism. If a sudden spike of traffic occurs—say, a flash sale or a viral video—the load is automatically distributed across thousands of edge nodes globally, rather than bottling up in a single data center.
Real-World Use Cases of Serverless 2.0
Edge computing isn’t just for caching; it’s powering complex logic.
Real-Time APIs and Microservices
Developers are moving critical microservices to the edge.
- Authentication: Verifying JWT tokens at the edge ensures unauthorized requests are blocked before they ever touch the core infrastructure.
- A/B Testing: Edge functions can randomly assign users to different test groups and serve different content variants instantly, without client-side flicker.
IoT and Event-Driven Systems
With billions of IoT devices coming online, sending all that sensor data to a central cloud is inefficient. Edge functions can process, filter, and aggregate IoT data locally (e.g., in a smart factory or city), sending only the necessary insights to the main database.
AI Inference and Personalization
Running massive AI training models requires central GPUs, but inference (using the model) is moving to the edge. An eCommerce site can run a personalization algorithm on the edge node to re-rank products for a specific user based on their browsing history, all within the milliseconds it takes to load the page.
Gaming, Streaming, and Fintech
- Streaming: Dynamic ad insertion in video streams happens at the edge to prevent buffering.
- Fintech: Edge functions can enforce geo-fencing rules for banking apps, ensuring compliance based on the user’s exact physical location.
Popular Serverless 2.0 Platforms Powering the Edge
Several key players are leading the charge in edge-native serverless.
Cloudflare Workers
A pioneer in the space, Cloudflare Workers runs on the V8 JavaScript engine across Cloudflare’s massive global network.12 It is known for exceptional speed and a developer-friendly experience with integrated key-value storage (KV).
AWS Lambda@Edge
An extension of the classic Lambda, this service allows you to run code at AWS CloudFront locations.13 It is powerful for manipulating requests and responses but can be more complex to configure than newer, edge-native competitors.
Vercel Edge Functions
Built on top of Cloudflare’s infrastructure but optimized for frontend workflows (especially Next.js), Vercel makes deploying edge middleware seamless for frontend developers.
Deno Deploy
Created by the founder of Node.js, Deno Deploy is a globally distributed serverless system that supports TypeScript out of the box.15 It emphasizes web standards and removes the need for complex configuration files.
Benefits and Challenges of Serverless 2.0
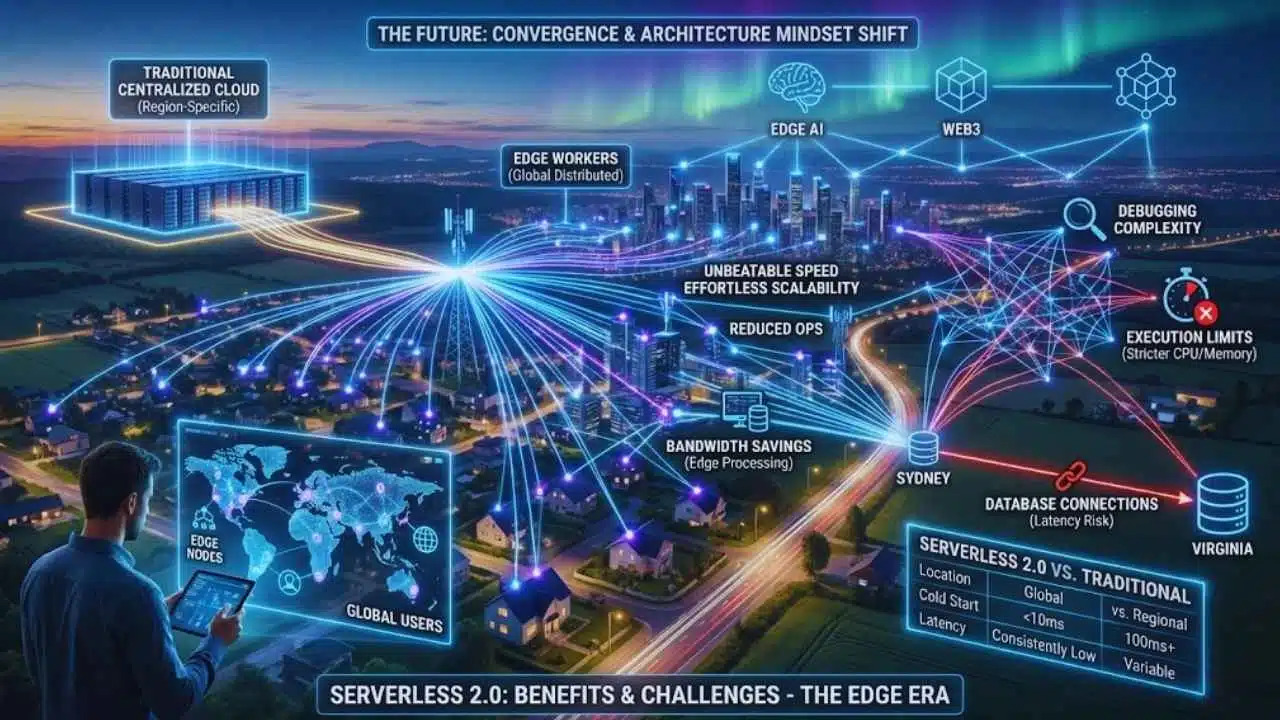
Is the edge right for every application? Not necessarily.
Key Benefits
- Speed: Unbeatable low-latency performance for global users.
- Scalability: effortless handling of traffic spikes without managing auto-scaling groups.
- Reduced Ops: “No Ops” is closer to reality; there are no regions to manage.
- Bandwidth Savings: Processing data at the edge reduces the amount of data that needs to travel to and from centralized clouds.
Current Limitations
- Debugging Complexity: Troubleshooting distributed systems is harder than debugging a local container.17 Logs may be scattered or delayed.
- Execution Limits: Edge functions often have stricter CPU time and memory limits compared to centralized cloud functions (e.g., 10ms vs 15 minutes).
- Database Connections: While compute is at the edge, most databases are still centralized. Connecting to a legacy SQL database in Virginia from an edge node in Sydney can negate the latency benefits.
Serverless 2.0 vs. Traditional Serverless
| Feature | Traditional Serverless (e.g., Standard Lambda) | Serverless 2.0 (e.g., Edge Workers) |
| Location | Region-specific (Centralized) | Global (Distributed Edge) |
| Cold Start | 100ms – 1s+ (Container-based) | < 10ms (Isolate-based) |
| Use Case | Heavy computation, long-running tasks | Routing, auth, personalization, lightweight logic |
| State | Stateless (connects to central DB) | Stateless (uses Edge KV/Durable Objects) |
| Latency | Variable based on distance | Consistently low |
The Future of Serverless and Edge Computing
We are only scratching the surface of what Serverless 2.0 can handle.
Convergence of Edge, AI, and Web3
The next phase will see heavy integration of Edge AI, where small, optimized models run entirely on edge nodes. Furthermore, decentralized Web3 applications are natural candidates for edge-native architecture, relying on distributed verification rather than central authority.
What Developers Should Prepare For
To thrive in this new era, developers need to shift their architecture mindset. The assumption that “the database is right next to the server” is no longer valid. Mastering patterns like eventual consistency, edge caching strategies, and distributed state management will be the defining skills for the next generation of cloud engineering.
Final Thoughts
Serverless 2.0 is more than just a buzzword; it is the logical evolution of the internet’s infrastructure. We have spent the last decade moving our hardware into the cloud to save money and increase agility. Now, we are moving our logic out of the cloud and into the network to reclaim performance.
While centralized cloud regions will always have a place for heavy data crunching and legacy storage, the future of user-facing applications lies at the edge. By adopting an edge-native mindset today, businesses aren’t just shaving milliseconds off their load times—they are future-proofing their architecture for a world that demands instant, intelligent, and global interaction.