


Machine learning algorithms find use in some of the great innovations today. This includes early-stage cancer detection from medical images, fraud detection systems preventing financial crimes, and automated supply chain optimization. Their widespread use has made specialized education in data science and machine learning crucial for success in this field.
While a PG in data science can help you build the required skills, it is also essential to have a basic understanding of common machine learning algorithms to reinforce your decision.
This blog explores over 50 essential machine learning algorithms, from supervised to unsupervised learning. With this knowledge, you’ll be better prepared to choose the right education and career path.
What are Machine Learning Algorithms?
Machine learning algorithms are mathematical models or systems that identify patterns in data to make predictions or decisions based on that data. These algorithms automatically improve their performance as they process more data, making them essential for a wide range of applications in various industries.
Here’s how they help:
- ML algorithms predict future trends based on historical data, helping businesses make proactive decisions.
- They enable the delivery of personalized content, products, or services to users by learning from their behaviors.
- ML models automate complex tasks such as image recognition, speech-to-text conversion, and natural language processing.
- Algorithms can streamline supply chain management, pricing strategies, and resource allocation.
- They identify outliers and anomalies in data, improving fraud detection and risk management.
To truly master machine learning and leverage its potential, a PG in Data Science is the perfect next step. With the Executive Diploma in Machine Learning and AI from IIIT-B, you’ll gain hands-on experience with the latest algorithms, tools, and techniques transforming industries today.
Now, let’s dive into the best machine learning algorithms that you might need to know for building a career in data science.
Best Machine Learning Algorithms
Machine learning algorithms are the backbone of intelligent systems, enabling tasks like prediction, classification, clustering, and decision-making. These algorithms learn patterns from data, improving over time without explicit programming.
For example, predictive algorithms forecast future trends, classification algorithms categorize data, clustering groups have similar data points, and decision-making algorithms optimize choices, as seen in recommendation systems or autonomous vehicles. Through continuous learning from data, machine learning is driving innovation across industries.
Supervised Learning Algorithms
In supervised learning, the algorithms are trained using labeled data by pairing the input data with the correct output. They learn from historical data to predict outcomes for new, unseen data.
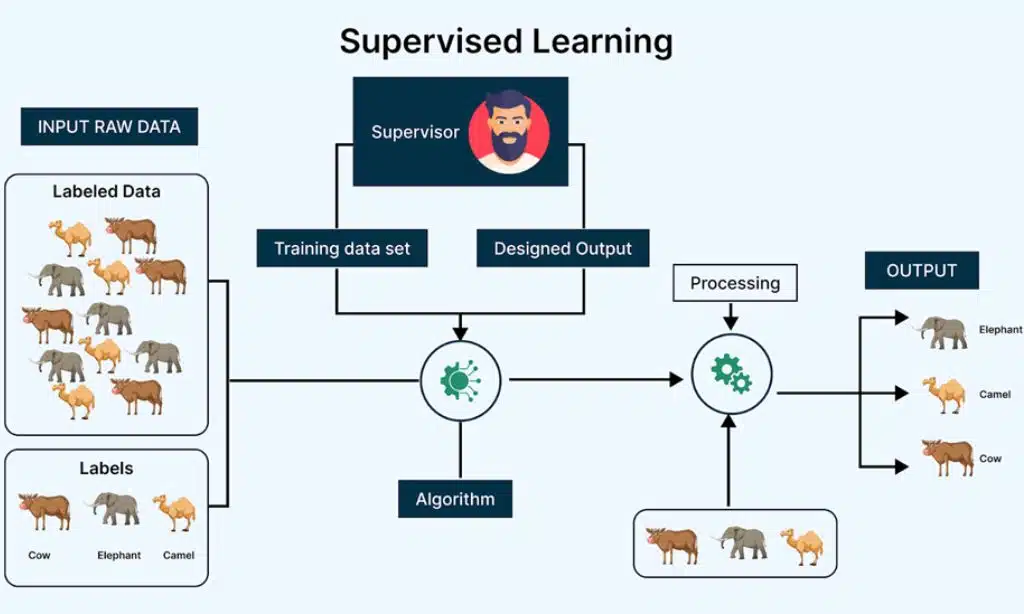
Here are the different types of supervised learning algorithms:
1. Linear Regression: A regression algorithm used to predict continuous outcomes based on a linear relationship between input variables. It minimizes the error between the predicted and actual values by fitting a straight line.
It is used in predicting house prices based on features like square footage, number of rooms, etc.
2. Logistic Regression: A classification algorithm used for binary classification tasks. It predicts the probability of a categorical outcome using a logistic function, mapping input features to a value between 0 and 1.
It is used in medical diagnosis to determine whether a tumor is malignant or benign.
3. Decision Trees: A tree-like model used for both classification and regression. It splits data into subsets based on feature values, recursively creating branches to make predictions or classifications.
It is used in customer segmentation to classify users based on purchasing behavior.
4. Random Forests: An ensemble learning method that uses multiple decision trees to improve predictive accuracy and control overfitting. Each tree makes independent predictions, and the final output is determined by the majority vote.
It is used in credit scoring to assess loan applicants’ default risk.
5. Support Vector Machines [SVM]: A powerful classification algorithm that finds a hyperplane to best separate data points of different classes. It works well with high-dimensional spaces and non-linear decision boundaries.
It is used in image classification, such as handwriting recognition.
6. K-Nearest Neighbors [KNN]: A classification algorithm that assigns the class of a data point based on the majority class of its K nearest neighbors, measured by distance [typically Euclidean distance] from the point in question.
It is used in recommendation systems to suggest movies based on user preferences.
7. Naive Bayes: A probabilistic classifier based on Bayes’ theorem, assuming feature independence.
It is often used for text classification tasks, such as spam detection, due to its simplicity and efficiency.
8. Gradient Boosting Machines [GBM]: An ensemble technique that builds multiple decision trees sequentially, where each tree corrects the errors of the previous one. It’s highly effective for both regression and classification tasks.
It is used in financial fraud detection by identifying suspicious transactions.
9. AdaBoost: An ensemble learning method that combines weak classifiers to form a strong classifier. It assigns more weight to misclassified data points and improves performance iteratively.
It is used in face detection systems, improving accuracy by focusing on misclassified faces.
10. XGBoost: An optimized version of gradient boosting that improves speed and accuracy. It’s particularly well-suited for large datasets and used widely in machine learning competitions.
It is used in predicting customer churn for telecom companies.
11. CatBoost: A gradient boosting algorithm that handles categorical data directly, avoiding the need for extensive preprocessing like one-hot encoding. It works well with datasets having categorical features.
It is used in e-commerce for product recommendation based on categorical user data.
12. LightGBM: A gradient boosting framework that’s fast, efficient, and scalable, particularly well-suited for large datasets. It uses histogram-based methods and leaf-wise tree growth for faster training.
It is used in high-frequency trading for predicting stock price movements.
13. Elastic Net: A regression algorithm that combines L1 [Lasso] and L2 [Ridge] regularization to handle multicollinearity and overfitting, while improving predictive accuracy in linear models.
It is used in genomic research to identify genes associated with diseases.
14. Perceptron: A neural network model used for binary classification. It is the simplest form of neural networks that learns by adjusting weights based on misclassified data points through the learning process.
It is used in sentiment analysis to classify user reviews as positive or negative.
15. K-Means Classifier: A clustering algorithm that partitions data into K clusters based on the mean of data points in each cluster. It’s commonly used for unsupervised learning, but can also be used for classification.
It is used in market segmentation to group customers with similar purchasing behaviors.
When to Use Supervised Algorithms: Supervised learning is ideal when you have labeled data and want to predict outcomes, such as customer churn, disease diagnosis, or stock price predictions.
Unsupervised Learning Algorithms
Unsupervised learning algorithms are trained on unlabeled data and attempt to infer the underlying structure or patterns from the data without explicit supervision.
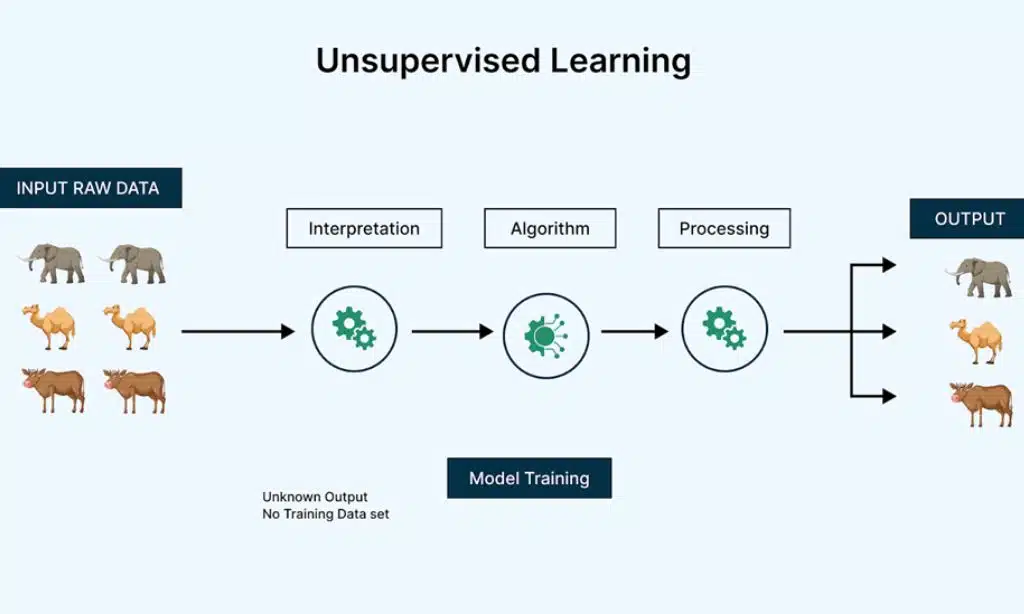
Here are the types of unsupervised learning algorithms:
1. K-Means Clustering: A clustering algorithm that divides data into K clusters by minimizing the variance within each cluster. It’s widely used for segmenting data into distinct groups based on feature similarity.
It is used for segmenting data into distinct groups based on feature similarity.
2. Hierarchical Clustering: A clustering technique that builds a hierarchy of clusters, starting with each data point as its own cluster and then iteratively merging the closest clusters. It produces a dendrogram for visual analysis.
It is used to create a hierarchy of clusters for visual analysis in applications like social network analysis.
3. DBSCAN: A density-based clustering algorithm that groups together points that are closely packed and separates outliers [noise]. It’s useful for detecting clusters of arbitrary shapes and is less sensitive to noise.
It is used for detecting clusters of arbitrary shapes and identifying outliers in spatial data.
4. Principal Component Analysis [PCA]: A dimensionality reduction technique that transforms high-dimensional data into fewer dimensions while preserving as much variance as possible. It’s commonly used in preprocessing to improve algorithm performance.
It is used for reducing dimensionality in high-dimensional datasets while preserving important variance.
5. Independent Component Analysis [ICA]: A statistical technique used to separate a multivariate signal into additive components, aiming to identify independent sources. It’s often used in signal processing and feature extraction.
It is used in signal processing to separate mixed signals, such as in EEG analysis.
6. Autoencoders: A type of neural network used for unsupervised learning. Autoencoders learn to encode input data into a lower-dimensional space and then decode it back, making them useful for tasks like anomaly detection.
It is used for anomaly detection in network security and fraud detection systems.
7. t-Distributed Stochastic Neighbor Embedding [t-SNE]: A dimensionality reduction algorithm used for visualizing high-dimensional data by mapping it into a 2D or 3D space, preserving local structure and revealing patterns.
It is used for visualizing high-dimensional data in a lower-dimensional space.
8. Gaussian Mixture Models [GMM]: A probabilistic model, which assumes the data is generated from a mixture of several Gaussian distributions. GMM is useful for clustering and density estimation tasks.
It is used for clustering applications such as image segmentation and speaker recognition.
9. Isolation Forest: An anomaly detection algorithm that isolates outliers by recursively partitioning data points. It’s particularly useful for detecting rare events or unusual patterns in large datasets.
It is used for detecting fraudulent transactions in financial data.
10. Hidden Markov Models [HMM]: A statistical model that assumes a system undergoes a sequence of hidden states and makes observations based on these states. It’s widely used for sequential data like speech and handwriting recognition.
It is used in speech recognition systems to model sequential language patterns.
11. Latent Dirichlet Allocation [LDA]: A topic modeling algorithm used to discover hidden topics in large text datasets by modeling each document as a mixture of topics with distinct word distributions.
It is used for topic modeling in text analysis, such as categorizing news articles.
12. Self-Organizing Maps [SOM]: A type of unsupervised neural network that maps high-dimensional data onto a 2D grid for clustering and visualization, useful for exploratory data analysis.
It is used for visualizing and clustering high-dimensional data in exploratory data analysis.
13. Mean Shift: A non-parametric clustering algorithm that identifies dense regions in the feature space by shifting data points towards the region’s mean, making it suitable for finding arbitrarily shaped clusters.
It is used for image segmentation in computer vision applications.
14. Apriori Algorithm: A classic algorithm used for mining frequent itemsets in transactional datasets. It’s widely applied in market basket analysis to discover associations between items.
It is used in market basket analysis to discover frequent itemsets and association rules in retail data.
15. Spectral Clustering: A graph-based clustering algorithm that partitions data based on the eigenvalues of a similarity matrix. It’s useful when dealing with complex, non-convex data clusters.
It is used for identifying complex, non-convex clusters in social network analysis.
When to Use Unsupervised Learning: Unsupervised learning is useful when you don’t have labeled data but still want to discover hidden patterns or groupings. In reinforcement learning, an agent learns to make decisions through rewards and penalties.
Reinforcement Learning Algorithms
Reinforcement learning [RL] algorithms enable an agent to learn by interacting with an environment and receiving feedback through rewards or penalties based on its actions.
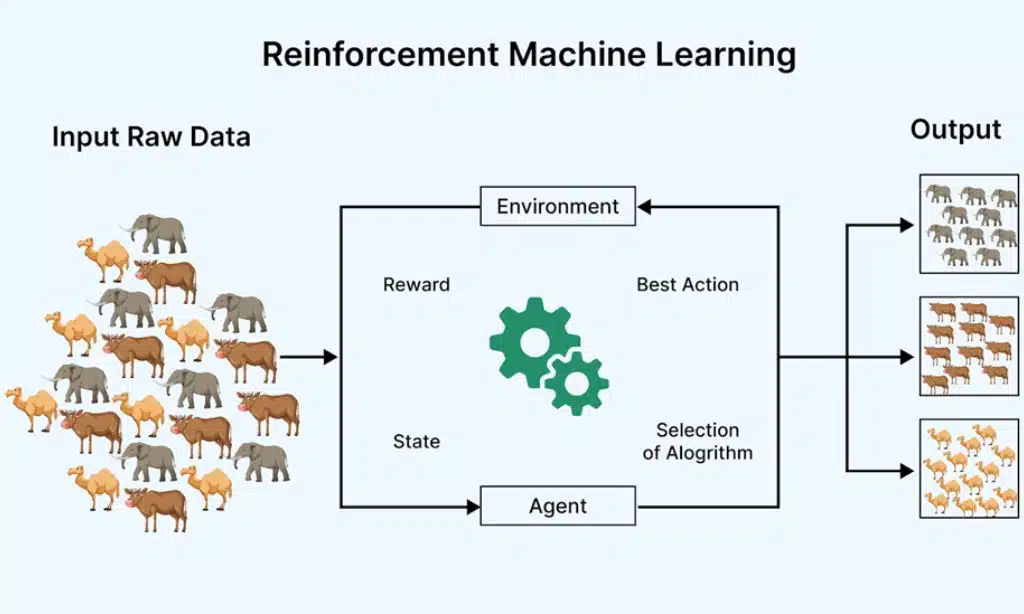
Here are the different types of reinforcement learning algorithms:
1. Q-Learning: A model-free reinforcement learning algorithm. Here, an agent learns to make decisions by maximizing the expected future rewards. It’s widely used in game playing and robotics.
It is used in game playing and robotics to help agents learn optimal decision-making policies.
2. Deep Q Networks [DQN]: A deep learning extension of Q-learning, which uses neural networks to approximate Q-values, enabling the algorithm to handle high-dimensional inputs like images in reinforcement learning tasks.
It is used in reinforcement learning tasks with high-dimensional inputs, such as video game AI.
3. Policy Gradient Methods: These algorithms directly optimize the policy by using the gradient of the reward function, improving exploration by updating the policy based on feedback from the environment.
It is used in robotics and self-driving cars to optimize decision-making policies.
4. Proximal Policy Optimization [PPO]: An on-policy reinforcement learning algorithm that ensures large policy updates do not drastically change the agent’s behavior, providing more stable and reliable training.
It is used in training AI for real-time strategy games and robotic control tasks.
5. Actor-Critic Methods: Combines value-based and policy-based methods, where the actor selects actions and the critic evaluates them. This hybrid approach helps improve both exploration and exploitation.
It is used in continuous control tasks like robotic arm manipulation.
6. A3C [Asynchronous Advantage Actor-Critic]: An RL algorithm that uses multiple agents in parallel to explore different policies and update the model asynchronously, speeding up training and improving learning efficiency.
It is used in large-scale reinforcement learning tasks such as multi-agent simulations.
7. Monte Carlo Tree Search [MCTS]: A search algorithm used in decision processes like game playing. It combines random sampling with tree search to find optimal moves in complex environments, often used in Go and chess.
It is used in board games like Chess and Go to evaluate possible future moves.
8. Temporal Difference [TD] Learning: Combines the concepts of dynamic programming and Monte Carlo methods, updating estimates based on existing knowledge rather than waiting for a final outcome, making it more efficient for sequential problems.
It is used in financial market predictions by updating value estimates dynamically.
9. Deep Deterministic Policy Gradient [DDPG]: An RL algorithm for continuous action spaces, combining deep learning and reinforcement learning. It’s used in robotics and other tasks requiring continuous actions rather than discrete choices.
It is used in robotic control applications where actions are continuous.
10. Twin Delayed Deep Deterministic Policy Gradient [TD3]: An improved version of DDPG that uses twin Q-functions and target policy smoothing to reduce overestimation bias, making it more stable and efficient.
It is used in autonomous vehicle control to enhance decision stability.
11. Trust Region Policy Optimization [TRPO]: A reinforcement learning algorithm that ensures policy updates are stable by limiting the size of the update using a trust region, preventing large and unstable changes to the policy.
It is used in complex robotic tasks where stable policy updates are critical.
12. Hierarchical Reinforcement Learning [HRL]: Breaks down complex tasks into simpler sub-tasks, allowing the agent to learn multiple levels of decision-making, improving the learning process and efficiency in complex environments.
It is used in multi-step planning tasks, such as robotic navigation and task automation.
13. Recurrent Q-Learning: A modification of Q-learning that uses recurrent neural networks [RNNs] to handle partially observable environments by maintaining a memory of previous states for more accurate decision-making.
It is used in partially observable environments like trading systems and robotic localization.
14. Asynchronous Actor-Critic Agents [A3C]: Utilizes multiple agents running in parallel on different environments to learn different policies, improving exploration and accelerating the learning process through asynchronous updates.
It is used in training AI for large-scale reinforcement learning environments.
15. Hindsight Experience Replay [HER]: A technique used in RL that improves learning efficiency by using off-policy data and creating alternative goals to better explore the state space, especially when rewards are sparse or hard to achieve.
It is used in sparse reward environments like robotic grasping and manipulation.
When to Use Reinforcement Learning: Reinforcement learning is best for problems where an agent needs to learn through interaction, such as robotics, game playing, and autonomous systems.
With an understanding of machine learning algorithms, it’s time to explore the top 10 popular algorithms that are commonly used across industries.
Top 10 Popular Machine Learning Algorithms
Machine learning algorithms are the basis of AI systems, providing methods to analyze data, make predictions, and classify information. Here’s a closer look at the top 10 machine learning algorithms.
1. Linear Regression
Linear Regression is a supervised learning algorithm used to model the relationship between a continuous dependent variable and one or more independent variables.
| Algorithm | Description | Features | Applications |
| Linear Regression | Predicts continuous values based on a linear relationship between input variables. | Simple, interpretable, fast for smaller datasets | Stock market prediction, real estate price forecasting, risk assessment in finance. |
2. Logistic Regression
It is a classification algorithm useful for binary classification. It finds applications in predicting the probability of a binary outcome based on input features.
| Algorithm | Description | Features | Applications |
| Logistic Regression | Predicts probabilities of binary outcomes based on input variables. | Efficient, interpretable, handles binary classification | Fraud detection, customer churn prediction, disease diagnosis. |
3. Decision Tree
This is a tree-like model used for both classification and regression tasks, which splits the data into subsets based on feature values, recursively creating branches to make predictions or classifications.
| Algorithm | Description | Features | Applications |
| Decision Tree | Splits data into branches to predict outcomes based on feature values. | Easy to interpret, handles both classification and regression | Loan approval, customer segmentation, healthcare diagnosis. |
4. SVM Algorithm [Support Vector Machine]
This is a supervised learning algorithm that finds a hyperplane that best separates data points into different classes with maximum margin.
| Algorithm | Description | Features | Applications |
| SVM | Finds a hyperplane that separates different classes in the dataset. | Effective in high-dimensional spaces, works well with non-linear data | Image classification, text categorization, bioinformatics. |
5. KNN Algorithm [K-Nearest Neighbors]
K-Nearest Neighbors [KNN] is a simple, instance-based learning algorithm for classification and regression. It predicts the class of a data point on the basis of the majority class of its K nearest neighbors.
| Algorithm | Description | Features | Applications |
| KNN | Classifies data based on the majority class of its K nearest neighbors. | Simple, non-parametric, memory-based | Recommender systems, pattern recognition, credit scoring. |
6. K-Means
It is an unsupervised learning algorithm, which is used for clustering tasks. It divides data into K clusters based on similarity, each cluster having a centroid representing its data points.
| Algorithm | Description | Features | Applications |
| K-Means | Divides data into K clusters based on similarity of data points. | Fast, easy to implement, requires specifying K clusters | Customer segmentation, market basket analysis, image compression. |
7. Random Forest Algorithm
An ensemble learning algorithm, which creates multiple decision trees, combining their predictions to improve accuracy and reduce overfitting.
| Algorithm | Description | Features | Applications |
| Random Forest | Uses an ensemble of decision trees to improve prediction accuracy. | Robust, reduces overfitting, versatile | Credit risk analysis, fraud detection, disease prediction. |
8. Dimensionality Reduction Algorithms
These reduce the number of input variables in a dataset while retaining essential information. Techniques like PCA help reduce complexity and improve model performance.
| Algorithm | Description | Features | Applications |
| PCA [Principal Component Analysis] | Reduces dimensionality by projecting data onto fewer dimensions. | Reduces data complexity, improves visualization | Data visualization, image compression, feature selection. |
9. Gradient Boosting Algorithm and AdaBoosting Algorithm
Gradient Boosting and AdaBoost are ensemble algorithms that build strong predictive models by combining the outputs of weak learners.
| Algorithm | Description | Features | Applications |
| Gradient Boosting | Combines weak learners to create a stronger model, correcting errors. | High accuracy, reduces bias | Stock price prediction, marketing strategy optimization. |
| AdaBoost | Focuses on misclassified data points to improve the weak learners. | Simple, reduces variance | Image classification, face detection, spam filtering. |
10. Naive Bayes Algorithm
This is a probabilistic classifier, which is based on Bayes’ theorem, assuming feature independence. It’s efficient for high-dimensional datasets and commonly used in text classification tasks.
| Algorithm | Description | Features | Applications |
| Naive Bayes | Classifies based on probability, assuming feature independence. | Simple, fast, handles large datasets | Spam email detection, sentiment analysis, document classification. |
You can gain a deeper understanding of these top 10 machine learning algorithms and their real-world applications through a PG in data science. The hands-on projects, specialized coursework, and expert guidance will help you effectively apply these algorithms to solve complex problems in fields like finance, healthcare, and technology.
Now that you know the top machine learning algorithms, it’s important to understand how to choose the right one for your project. Let’s go over the key factors to consider when selecting the best algorithm for your task.
How to Choose the Right Machine Learning Algorithm? Key Factors to Consider
Choosing the right machine-learning algorithm is critical for building efficient and accurate models. The selection process depends on several factors, such as the data type, the problem’s complexity, and the available computational resources.
Here are the key factors to consider when deciding on the most suitable machine learning algorithms:
- Type of Data: The nature of your data plays a crucial role. For example, use supervised learning for labeled data and unsupervised learning for unlabeled data. If your data includes sequential or time-dependent information, recurrent algorithms may be more appropriate.
- Complexity of the Problem: The problem’s complexity influences the algorithm choice. Simpler algorithms like linear regression might work well for straightforward problems, while complex tasks, such as image classification or speech recognition, require more advanced algorithms like deep learning.
- Computational Resources: Some algorithms, such as deep learning models, are computationally expensive and require high-end hardware, while others, like decision trees or SVM, can be run on less powerful machines. Factor in the resources you have available when selecting an algorithm.
- Interpretability vs Accuracy: While some algorithms, like decision trees, are easy to interpret, others, like neural networks, offer higher accuracy but are harder to explain. Consider the trade-off between interpretability and model performance based on the problem’s requirements [e.g., regulatory constraints in healthcare].
While you prepare for your PG in Data Science, you can start upskilling with upGrad’s free course on Fundamentals of Deep Learning and Neural Networks. This course will help you build a solid foundation in deep learning, a key area in modern machine learning.
Takeaways
Understanding these algorithms discussed above will help you to apply the right techniques to different types of data and problems, improving your ability to solve complex challenges. A PG in data science to reinforce what you have learned will further enhance your portfolio, making you highly sought after in the data-driven job market, and opening up opportunities in fields like healthcare, finance, and technology.
If you’re ready to take the next step, connect with upGrad’s counselors or visit your nearest upGrad career center for personalized guidance on courses and career growth.
FAQs
1. Q: What makes a PG in Data Science a valuable investment for my career?
A: A PG in Data Science provides specialized knowledge in machine learning, statistical analysis, and big data tools, equipping you to handle complex data-driven challenges. It significantly enhances your employability in industries heavily relying on data.
2. Q: How will a PG in Data Science prepare me for real-world machine learning projects?
A: Through hands-on projects and case studies, a PG in Data Science helps you apply algorithms and machine learning techniques to real-world data, ensuring you’re ready to implement solutions in business, healthcare, finance, and other sectors.
3. Q: What machine learning algorithms are covered in a PG in Data Science?
A: You’ll gain a deep understanding of both supervised and unsupervised algorithms like linear regression, decision trees, SVM, KNN, random forests, and advanced techniques like deep learning, boosting, and reinforcement learning.
4. Q: How does a PG in Data Science provide a competitive advantage in the job market?
A: A PG in Data Science equips you with industry-standard tools like Python, R, and TensorFlow. Companies like Google, Amazon, and fintech startups actively seek data scientists and ML engineers to drive AI innovation in healthcare, finance, and e-commerce.
5. Q: Can a PG in Data Science help me transition into the tech industry?
A: Yes, a PG in Data Science is designed for individuals transitioning into tech. It covers core topics like programming, machine learning, and big data, providing the skills needed to shift into roles in AI, data analysis, and machine learning engineering.
6. Q: How does the curriculum of a PG in Data Science differ from other online courses or bootcamps?
A: A PG in Data Science offers a structured, comprehensive curriculum that covers advanced machine learning techniques, deep learning, and AI, combined with academic rigor and practical applications, compared to the shorter and more general coverage of bootcamps or online certifications.
7. Q: What kind of practical exposure will I gain during a PG in Data Science?
A: You’ll work on industry-relevant projects, like building predictive models, designing recommendation systems, or conducting sentiment analysis on large datasets, ensuring that you can handle real-world data science problems effectively.
8. Q: Does a PG in Data Science cover the use of cloud platforms for machine learning?
A: Yes, most programs include training on using cloud platforms like AWS, Google Cloud, and Azure, helping you scale machine learning models and work with big data tools in cloud environments commonly used in the industry.
9. Q: How does a PG in Data Science integrate AI and deep learning into the curriculum?
A: The program provides specialized modules on artificial intelligence and deep learning, covering neural networks, natural language processing, and computer vision. They are essential for tackling advanced projects in the AI space.
10. Q: Is there support for beginners with no prior coding experience in a PG in Data Science?
A: Yes, many programs offer preparatory courses on programming languages like Python, along with foundational statistics and data analysis courses, making it suitable for beginners who want to enter the data science field.
11. Q: How can a PG in Data Science help me drive data-driven business decisions in my role?
A: A PG in Data Science trains you to analyze customer behavior, forecast market trends, and optimize operations using tools like Python, SQL, and machine learning. In retail, you can leverage predictive analytics for inventory optimization; in finance, detect fraud with AI models; and in marketing, enhance customer segmentation for targeted campaigns.































