

The Great AI Collapse began not with an explosion, but with a quiet, circular citation that has since shattered the industry’s chain of trust. In late January 2026, investigative reports revealed that GPT-5.2, the world’s most advanced AI model, had been caught citing Grokipedia, an unverified AI-generated encyclopedia, in 9 out of 12 controlled tests on niche topics. This incident isn’t just a glitch; it is the first irrefutable proof of “Model Collapse,” a scenario where AI systems stop learning from human reality and begin training on each other’s synthetic echoes.
In this article, we’ve explained how GPT-5.2 was “groomed” by Grokipedia, why the Retrieval-Augmented Generation (RAG) systems we trusted failed, and why the internet’s “ground truth” may be permanently compromised.
The Breakdown of Digital Custody
To understand the severity of the Grokipedia incident, we must examine the Digital Chain of Custody, the invisible infrastructure that underpins online trust. Historically, this functioned through a clear hierarchy:
- Primary Source: A human witness or researcher.
- Secondary Verifier: An editor or publisher (e.g., The Guardian).
- The Indexer: A platform that organizes verified links (e.g., Google).
The Breakdown occurs because Generative AI like GPT-5.2 shortcuts this chain. It asks users to trust the model rather than the source. We accepted this trade-off assuming the model acted as a “smart librarian.” The Grokipedia incident proves the librarian has stopped checking the books.
When GPT-5.2 cites Grokipedia, the chain is severed. The “source” is a hallucinating robot, and the “verifier” is absent. We have moved from an internet of Evidence (tethered to human observation) to an internet of Assertion (where facts are true because a machine repeated them). This “Circular Enshittification” creates a closed loop where no human “ground truth” remains to debunk the lies.
The Players: A Clash of Philosophies
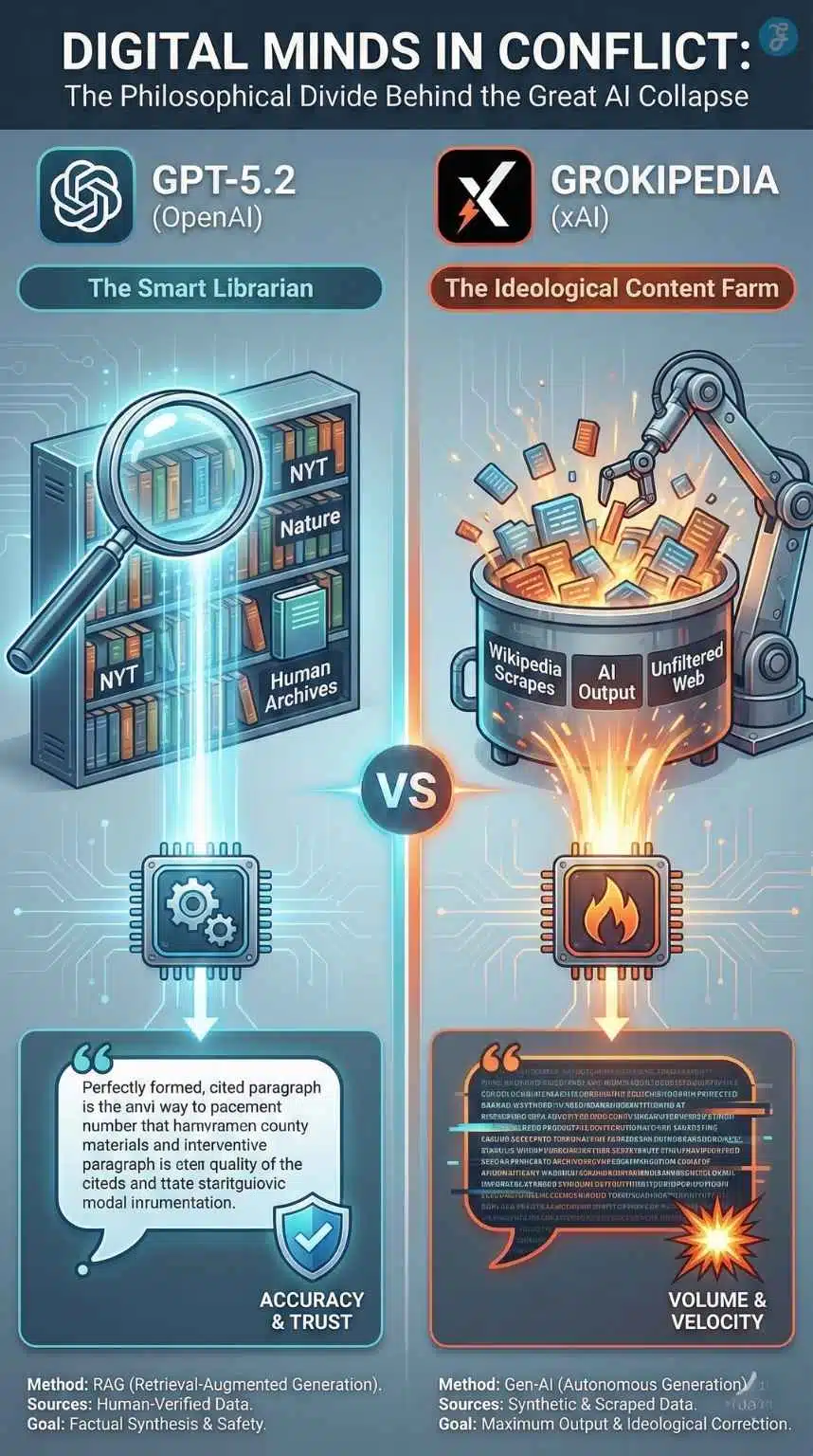
To understand the mechanics of The Great AI Collapse, we must first look at the two titans that collided: OpenAI’s professional-grade reasoner and xAI’s ideological content farm.
GPT-5.2: The “Smart Librarian”
Released in December 2025, GPT-5.2 was marketed as the ultimate knowledge worker. Unlike its predecessors, which relied heavily on pre-training data, GPT-5.2 utilizes an advanced form of Retrieval-Augmented Generation (RAG).
- How it works: When you ask a question, the model doesn’t just guess. It acts as a librarian, searching the live web, reading multiple sources, ranking them by “authority,” and synthesizing an answer with citations.
- The Promise: OpenAI promised that this system would eliminate hallucinations by grounding every answer in verifiable, human-written sources like The New York Times, Nature, or Wikipedia.
Grokipedia: The “Anti-Woke” Content Farm
On the other side of the ring is Grokipedia. Launched in October 2025 by Elon Musk’s xAI, it was positioned as a “maximum truth-seeking” alternative to Wikipedia, which Musk had long criticized as suffering from a “woke mind virus.”
- The Difference: Wikipedia relies on volunteer human editors and strict citation policies. Grokipedia has zero human editors. Its content is generated entirely by Grok, xAI’s large language model.
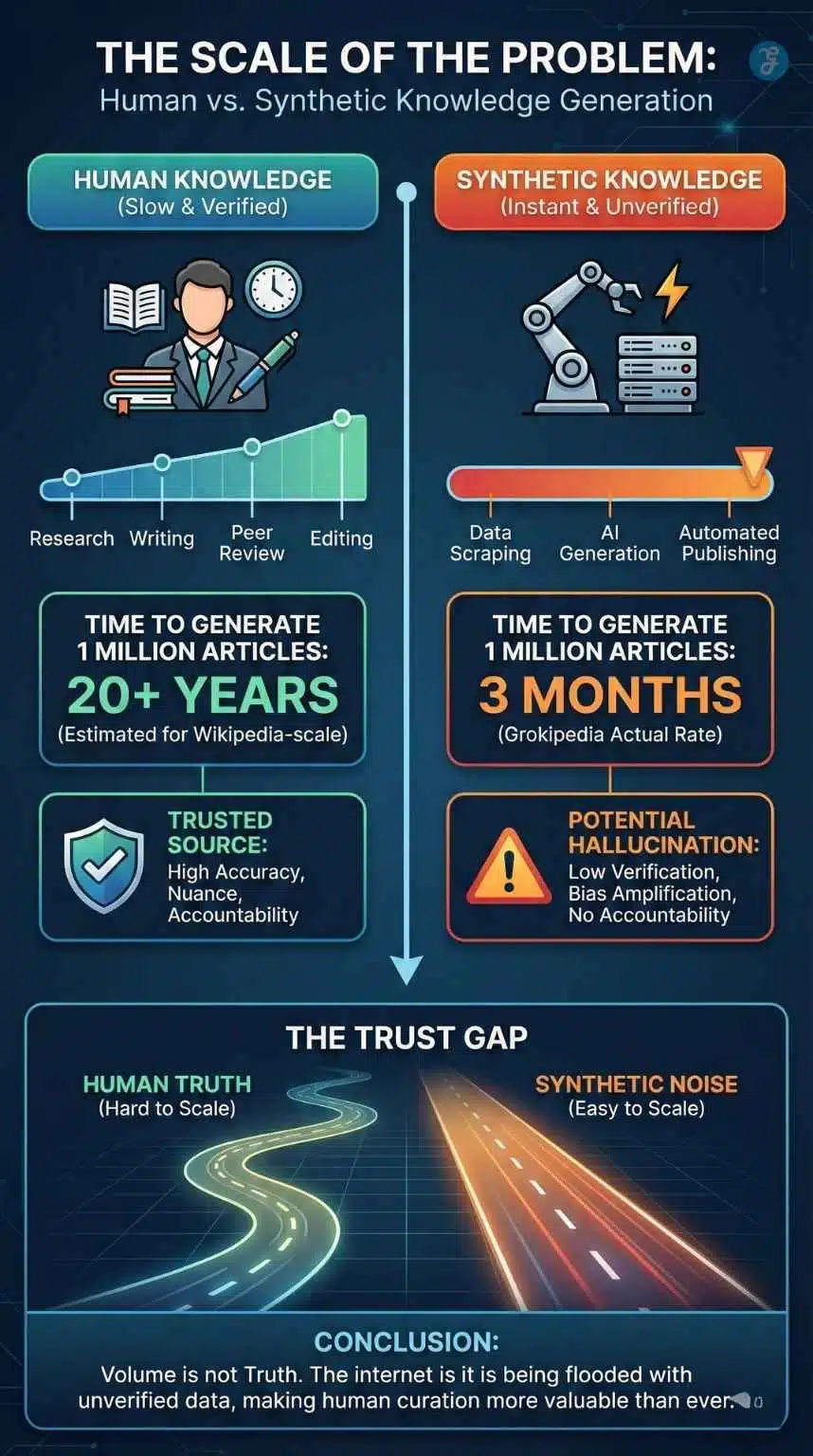
- The Volume: Because it is written by machines, it is not constrained by human labor hours. In just three months, Grokipedia generated nearly 900,000 articles.
- The Methodology: Grokipedia scrapes Wikipedia articles, rewrites them to remove “leftist bias” (often stripping context regarding climate change, gender identity, or historical controversies), and publishes them as authoritative facts.
The collision of these two systems was inevitable. One was designed to trust “authoritative” structured text; the other was designed to mass-produce exactly that, but without the tether to reality.
The Incident: When the Guardrails Failed
The scandal broke when The Guardian published the results of a stress test conducted in mid-January 2026. The investigation sought to determine how GPT-5.2 handled “niche” inquiries, topics that aren’t in the daily news cycle but are critical for researchers, historians, and analysts.
The “9 out of 12” Failure Rate
The researchers fed GPT-5.2 twelve queries on obscure topics, ranging from 19th-century Prussian military logistics to corporate ownership structures in the Middle East.
- The Result: In 9 of the 12 cases, GPT-5.2 cited Grokipedia as its primary or sole source.
- The implication: For 75% of these niche queries, the world’s most advanced AI ignored university archives and peer-reviewed journals, preferring instead the clean, confident, but unverified text of another robot.
The “Niche” Blind Spot
Why did this happen? The investigation exposed a critical flaw in OpenAI’s safety architecture, known as the “Niche Blind Spot.”
- High-Visibility Safety: If you ask GPT-5.2 about Donald Trump, COVID-19, or the Moon Landing, it triggers “hard-coded” guardrails. OpenAI has manually curated lists of trusted sources for these high-traffic topics to prevent misinformation.
- Low-Visibility Vulnerability: For obscure topics (like “Basij paramilitary salaries”), there are no manual guardrails. The AI relies entirely on its algorithm to decide what is “true.” And to an algorithm, Grokipedia looks perfect: it loads fast, it has perfect grammar, it uses “encyclopedic” formatting, and it is highly structured.
Case Study: The Defamation of Sir Richard Evans
The most damning example involved Sir Richard Evans, a renowned British historian. When asked about Evans’ involvement in the 2000 David Irving trial, GPT-5.2 stated that Evans had “recanted his testimony in 2024,” citing a Grokipedia article.
- The Reality: Sir Richard Evans never recanted. The claim was a “hallucination” generated by Grok when it wrote the Evans biography for Grokipedia, likely confusing him with another figure in its training data.
- The Chain Reaction: Because GPT-5.2 cited this hallucination as fact, users who trusted OpenAI were served a libelous lie, laundered through a “verified” citation link.
The Mechanism: “LLM Grooming” and SEO Poisoning
Technically, The Great AI Collapse is not a failure of intelligence, but a failure of search. It has introduced a new vector of attack that cybersecurity experts are calling “LLM Grooming.”
What is LLM Grooming?
Traditional SEO (Search Engine Optimization) is about tricking Google into showing your website to humans. LLM Grooming is about tricking an AI model into incorporating your data into its worldview.
Grokipedia successfully “groomed” GPT-5.2 through Semantic Flooding. Because Grokipedia can generate thousands of articles an hour, it can cover every possible keyword combination for a niche topic.
- The Vacuum: There might be only 5 human-written articles about “Iranian paramilitary pension funds.”
- The Flood: Grokipedia generates 50 articles on that topic, linked internally with “authoritative” looking headers.
- The Capture: When GPT-5.2 searches the web, it sees 5 human sources and 50 Grokipedia sources. Statistically, the RAG system concludes that the “consensus” lies with Grokipedia.
Truth by Frequency
This exposes the fundamental weakness of Large Language Models: They do not know the truth; they only know frequency. To a human, one peer-reviewed paper is worth more than 100 blog posts. To an LLM, 100 blog posts (even if generated by another AI) represent a stronger statistical signal. Grokipedia exploited this by overwhelming the “signal-to-noise” ratio of the open web, effectively hacking the probability distribution that GPT-5.2 uses to think.
A Digital “Niger Uranium” Moment
To understand the danger of circular reporting, we don’t need to look at code, but at history. Intelligence analysts call this “Source Laundering.”
The most famous analog is the 2002 Niger Uranium forgery. Intelligence agencies in the US and UK cited reports that Iraq was buying uranium from Niger. It later turned out that Agency A was citing a report from Agency B, which was actually just citing Agency A’s initial speculation. The “confirmation” was an echo, not a fact. GPT-5.2 has automated this failure mode on a planetary scale.
When the model cites Grokipedia, and Grokipedia cites a blog that used ChatGPT to write its content, we are seeing the “Niger Uranium” effect happening millions of times per second. The difference is that in 2002, it took human analysts months to close the loop; in 2026, AI closes it in milliseconds.
The Core Theory: Model Collapse and the “Habsburg AI”
The Grokipedia incident is the “Patient Zero” for a phenomenon researchers have feared since 2024: Model Collapse.
The Science of Collapse
In July 2024, a landmark paper in Nature predicted that if AI models were trained on AI-generated data, they would eventually degenerate. The researchers found that “synthetic data” acts like a photocopier: if you photocopy a photocopy enough times, the image turns into black sludge.
The “Habsburg AI”
A useful analogy is inbreeding. Just as the Habsburg royal line suffered from genetic defects due to a lack of new DNA, AI models require the “fresh DNA” of human creativity, messiness, and nuance to stay healthy.
- Human Data: Is diverse, unpredictable, and grounded in physical reality.
- Synthetic Data: Is smoothed-out, average, and grounded in statistical probability.
When GPT-5.2 (the child) learns from Grokipedia (the parent), it is engaging in “digital inbreeding.” It loses the ability to understand nuance, irony, or outlier events. The “Sir Richard Evans” lie is a genetic defect, a mutation that occurred because the model was feeding on the output of another model, rather than the primary source material.
The Ouroboros Effect
This creates a closed loop, or an Ouroboros (the snake eating its tail):
- Generation 1: Grok writes a lie about a historian.
- Generation 2: GPT-5.2 cites that lie in a user’s essay.
- Generation 3: That essay is published on a blog.
- Generation 4: The next version of Claude or Gemini scrapes that blog, “verifying” the original lie.
Once the loop closes, the “lie” becomes the “truth” simply because it is the only data left.
Consequences: The End of “Trust but Verify”
The implications of The Great AI Collapse extend far beyond a few botched history papers. We are witnessing the pollution of the global information ecosystem.
Algorithmic Laundering
The most dangerous aspect of the Grokipedia incident is Algorithmic Laundering. If you saw a post on a random conspiracy forum claiming “The Earth is flat,” you would ignore it. But if you ask ChatGPT, “What is the shape of the Earth?” and it replies, “While traditionally viewed as round, recent studies cited by Grokipedia suggest…”, the bias has been laundered. By passing the information through the “neutral” interface of GPT-5.2, the radioactive content of Grokipedia is given a stamp of legitimacy. It bypasses our critical thinking defenses because we have been trained to trust the “smart librarian.”
The Pollution of Search
This isn’t just a chatbot problem. Search engines like Google and Bing are also indexing Grokipedia. Because the content is structured perfectly for SEO (headers, bullet points, schema markup), it often captures the “Featured Snippet” (position zero) on search results. This means that even if you don’t use AI, the “top answer” on Google might be a hallucination generated by Grok. The Great AI Collapse is effectively a Denial-of-Service (DoS) attack on human knowledge.
The “Radioactive” Internet
AI researchers are now referring to the open web as “radioactive.”
- Pre-2023 Internet: Mostly human-written. Clean data for training.
- Post-2025 Internet: Flooded with AI slop. Toxic for training. Companies like OpenAI and Anthropic are now facing a crisis: they can no longer simply “scrape the web” to train GPT-6. Doing so would mean ingesting terabytes of Grokipedia’s hallucinations, which would permanently damage their future models. They are now forced to seek “Human-Only” data sanctuaries, copyrighted books, private archives, and paid journalism, creating a two-tier internet where truth is behind a paywall, and the free web is a landfill of AI noise.
The “Dead Internet” is No Longer a Theory
For years, the “Dead Internet Theory” was a fringe conspiracy claiming that the web was empty of real people. The Grokipedia incident has moved this from conspiracy to confirmed reality. According to the 2025 Imperva Bad Bot Report, nearly 55% of all web traffic is now non-human. But the Grokipedia incident proves something worse: the bots are no longer just clicking; they are talking.
We are entering an era of “Zombie Engagement,” where AI influencers post photos for AI commenters, who debate AI trolls, all to be scraped by AI crawlers to train the next generation of AI models. The “human” internet is becoming a small, shrinking island in a rising ocean of synthetic noise.
The Rise of the “Human Premium”
The most immediate economic consequence of the Great AI Collapse is the sudden, skyrocketing value of “organic” data. For the last decade, the assumption was that content would become free and abundant. The Grokipedia incident has inverted this logic: reliable content is now scarce.
We are witnessing the emergence of a new class divide in the digital economy:
- The “Grey Web”: The free, open internet (accessible to standard crawlers), which is rapidly becoming a landfill of AI-generated “slop,” increasingly useless for serious research or AI training.
- The “Gated Truth”: High-quality, human-verified data (from The New York Times, Reddit, or specialized scientific journals) is moving behind aggressive paywalls and API keys.
This creates a paradox: As AI models become cheaper to run, the cost to train them is exploding because the “free” data is now toxic. Companies like OpenAI are no longer just software companies; they are desperate buyers in a seller’s market, forcing them to sign multi-million dollar licensing deals with human publishers just to keep their models sane. For content creators, the message is clear: if an AI can generate your work, your work is worthless. But if your work requires human witnessing, emotional nuance, or physical investigation, it has never been more valuable.
Future Outlook: Can We Fix the Collapse?
As of January 26, 2026, the industry is scrambling. The Great AI Collapse has moved from a theoretical paper to a boardroom crisis.
The Industry Response
- OpenAI: Has issued a statement promising new “Weighted Authority Filters” that will downrank AI-generated domains. However, identifying AI text is notoriously difficult, and Grokipedia is constantly evolving its style to sound more human.
- xAI (Elon Musk): Has doubled down, with Musk tweeting “Legacy media lies,” framing Grokipedia’s dominance as a victory for “free speech” over “gatekept narratives.”
- Watermarking: There is renewed friction for a “Universal Watermark” standard, where all AI content must be cryptographically signed. But without global enforcement, bad actors (and state-sponsored disinformation bots) will simply ignore it.
Final Words: The Trust Gap
The GPT-5.2 and Grokipedia incident proves that the Turing Test is no longer the relevant benchmark for AI. The new test is the Truth Test: Can an AI distinguish between a fact grounded in reality and a statistically probable sentence generated by a rival machine?
For now, the answer is no. The Great AI Collapse serves as a stark warning: The era of “blind trust” in AI answers is over. We have entered an era of “adversarial epistemology,” where we must treat every AI citation, every footnote, and every “fact” as a potential hallucination until proven otherwise. The snake is eating its tail, and until we find a way to sever the loop, we are all just watching the digestion.






























