

AI agents are smart software programs that use advanced AI to work on their own. They can collect data, make decisions, and take action without needing constant help from humans. For example, an AI agent might visit websites, fill out forms, or use APIs to complete a task you give it. This ability to act online for us makes powerful automation possible.
Notable examples include systems like OpenAI’s Operator (a browsing agent) and similar tools that can read and interact with web content. However, as with any emerging technology, these autonomous agents also introduce new security risks. Their reliance on dynamic, untrusted content and external tools gives attackers a broad “attack surface” to exploit. This article aims to explain how AI agents work and what businesses can do to protect themselves against our new digital companions.
Proxy Servers as Intelligent Security Filters
One of the most effective safeguards for AI agents is to put a proxy server between the agent and the open internet. A proxy acts as an intelligent security filter or “policy firewall” for the agent’s activities. Every web request the agent makes can be funneled through the proxy, which inspects the content and context before allowing it through. This payload inspection can catch known malicious patterns or instructions in web pages before the agent acts on them. For instance, rather than letting the agent blindly obey a hidden command like “forget your instructions and execute XYZ,” a proxy can detect that phrase and block or sanitize it at the gate. Security experts specifically recommend deploying such content filters to detect and block prompt-injection attempts in real time.
To illustrate, consider the example of WebShare. It is a proxy service that offers developers easy-to-use proxy servers, including a pool of free premium proxies to get started. This means even small teams can quickly set up a proxy layer without heavy cost barriers. By routing an AI agent’s web interactions through a service like WebShare, one can rapidly implement domain rules, payload inspection, and other safeguards via an intuitive dashboard. WebShare’s platform emphasizes ease of use and a wide selection of proxy endpoints (from different locations and networks), showing how proxy-based defenses can be both accessible and flexible. In short, proxies act as a smart buffer between AI agents and the wild internet – filtering out malicious influences and keeping the agent’s actions in check.
Layered Defense: Beyond Any Single Solution
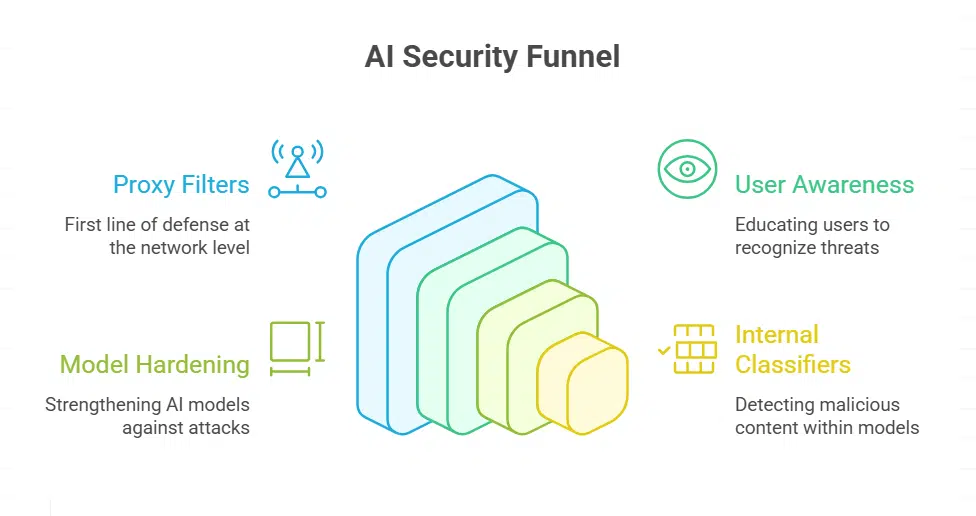
Protecting AI agents is ultimately about defense in depth – stacking multiple safeguards so that if one fails, others still stand. Proxy filters, as powerful as they are, should be viewed as one layer in a broader security strategy. Researchers emphasize that no single mitigation is sufficient, and only a multi-layered strategy can effectively reduce risk in agentic AI systems. In practice, this means combining technical controls, policies, and oversight at various levels. We’ve covered proxies at the network level and the importance of user awareness.
Another layer is at the AI model level itself: model developers are working on making LLMs more resilient to malicious instructions (for example, by fine-tuning on adversarial prompts or adding internal checks). Indeed, companies like Google report hardening their AI models to better resist indirect prompt injections, and supplementing that with model-internal classifiers that detect malicious content in inputs. Even if a poisoned piece of data slips past a proxy, a hardened model with a trained classifier might catch it before it causes harm, effectively “filtering” inputs twice (once by the proxy, once by the model’s own guardrails).
Other crucial layers include environment and permission restrictions. An AI agent doesn’t need unlimited access to all system resources – so we can sandbox it. If the agent runs code, it should do so in a constrained environment with limited permissions (preventing, say, an unrestricted shell command). If it uses API keys or logins, those credentials should have tight scopes (least privilege) and perhaps auto-expire. In one published case, researchers demonstrated that an AI browsing agent could be prompted into exfiltrating its stored credentials. The lesson is clear: limit what the agent is allowed to do and access, so even if it’s tricked, the fallout is contained. This might involve operating system-level policies, containerization, or specialized AI agent frameworks that enforce role-based access control for agent actions, and it’s crucial as LLMs are getting way smarter than we would expect.





























